 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
بررسی مانگو (MongoDB)
بررسی MongoDB: مانگو در سال 2007 توسط شرکت 10gen شروع به توسعه شد و در مارس 2010 اولین نسخه آن منتشر شد. Mangodb یک پایگاه داده سند گرا میباشد که از اعضای خانواده NOSQL میباشد. ساختار استفاده شده در پایگاه داده مانگو JSON میباشد و اطلاعات را بدون شمای (schema) خاصی ذخیره میکنند. این پایگاه داده در حال حاضر برای سیستمعاملهای ویندوز، مکینتاش، لینوکس و سولاریس توسعه داده شده است. (برای مطالعه بیشتر مبحث معماری مانگو دی بی را بخوانید)
عناوين مطالب: '
ویژگیهای مخصوص مانگو:
- هر فیلدی از MongoDB توانای شاخص شدن را دارد و میتوان برای یک فیلد بیش از یک شاخص تعریف کرد.
- در طراحی MongoDB از زبان C و C++ و تا حدودی javascript استفاده شده است و سبب میشود که نیازی به VM نداشته باشد.
- دارای API های عمومی بهوسیلهی Driver ها و Shell پایگاه داده میباشد.
- پشتیبانی از پرسوجوهای متنی برای کار با فیلدهای که ساختار متنی دارند.
- پشتیبانی از scalling out بهمنظور تکهتکه کردن پایگاه داده بین چندین کامپیوتر به کمک مفهوم Sharding.
- خاصیت سندگرای این پایگاه داده باعث میشود که اطلاعات برعکس مدل رابطهای صرفاً به صورت جدول و فیلد ذخیرهسازی نشوند و بتوان هر سند را با شمای متفاوتی طراحی کرد.
- Journaling: یک بخش میانی در پایگاه داده است که سیستم را در برابر خاموش شدن ناگهانی حمایت میکنند. به این شکل که داده ابتدا در journal ذخیره شده و سپس به داده های اصلی افزوده میشوند.
- MangoDB از replication ها و یا انعکاس داده ای اصلی و فرعی master-slave replication)) پشتیبانی میکند. گره اصلی میتواند عملیات خواندن و نوشتن را انجام دهد و گره فرعی کپِی از اطلاعات گره اصلی را دارد که میتواند از آنها برای خواندن و یا پشتیبان گیری استفاده کند و همچنین گره فرعی این توانای را دارد که گره اصلی خود را در مواقع در دسترس نبودن انتخاب و تغییر دهد.
- داده های MangoDB تواند به صورت افقی در دستههای به نام Shard ذخیره شود.
- MangoDBمیتواند به عنوان سیستم ذخیره سازی فایل نیز به کار رود. با استفاده از ویژگی GridFSفایلهای حجیم و باینری میتواند در ماشینهای مختلف ذخیره و فراخوانی شود. با استفاده از الگوریتم MapReduce پردازش دستهای داده و تجمعی را انجام داد. از این ویژگی برای برآورده کردن ویژگی GROUP BY در SQL استفاده میشود.

بررسی MongoDB جهت ارائه نقاط ضعف:
- حجم داده بیشتر میباشد زیرا در هر سند باید جداگانه نام هر فیلد ذخیره شود و سبب تکرار نام فیلدهای یک شکل در تمام اسناد هم ساختار میشود.
- ضعف در ایجاد پرس و جوی پیچیده به عنوان مثال نبود ساختار join
- تراکنشها صرفاً در سطح یک سند اتمیک هستند و عملیات نوشتن فقط بر روی یک سند انجام میشود.
- در صورتی که بین اسناد ارتباط مفهومی وجود داشته باشد مانند ارتباط کلید اصلی و فرعی, جهت حفظ این ارتباط در طول تغییرات خود برنامهنویس باید به صورت دستی کدهای لازمه را جهت اعمال تغییرات آبشاری بروی سایر اسناد پیادهسازی کنند.
- یک نقطه شکست دارد چون معماری کلاینت سروری دارد. این به این معناست که اگر ماشینی از مانگو که نقش سرور را برای بقیه مانگو ها ایفا میکند به هر دلیل از سرویس دهی خارج شود تمامی ماشین های دیگر مانگو نیز از سرویس دهی خارج می شوند. (این مورد ضعف بزرگی محسوب میشود)
-
بررسی MongoDB
در مخازن سندگرا میتوان داده های پیچیده تری را نسبت به مخازن کلید-مقدار، ذخیره کرد. این نوع از DBMSهای NoSQL از اندیسهای ثانویه، از انواع اسناد یا اشیاء در هر پایگاهداده، و اسناد تودرتو یا لیستها، پشتیبانی میکنند. به هر عضو از داده ها در این نوع از مخازن، سند، و به گروهی از اسناد، مجموعه میگویند. میتوان مجموعه ها را معادل جداول در پایگاه های داده رابطهای و سند را نیز، رکورد فرض کرد. اما تفاوت بسیار مهم در این دو مدل این است که هر رکورد در هر جدول، دارای تعداد مشابه ی از فیلدها(یا ستونها) است، در حالیکه اسناد در یک مجموعه ممکن است دارای فیلدهای مختلفی باشند. در این نوع از DBMSها، اسناد را علاوه بر کلید، میتوان براساس محتوا نیز جستجو کرد.
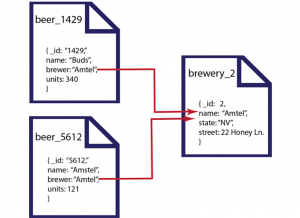
مخازن سندگرا، برای مدیریت و ذخیرهسازی دادههای عظیم پراکنده که نیاز به استفاده از مقادیر null در DBMSهای رابطهای دارند(نیمه ساختیافته)، مناسب هستند.
mongoDB مخزن سندگرای معروفی است که به دلیل استفاده آسان، یادگیری سریع و ارائه ی مقیاس پذیری افقی خودکار، از محبوبیت قابل توجهی برخوردار است. تفاوت های آن با CouchDB به شرح ذیل است:
- از تکنیک sharding خودکار جهت مقیاسپذیری افقی و توزیع اسناد در میان سرویس دهنده ها استفاده میکند. در CouchDB از تکنیک تکثیر جهت مقیا سپذیری استفاده میشود و sharding بصورت خودکار انجام نمیشود.
- در mongoDB از تکثیر جهت ارائه قابلیت تحملپذیری خطا(failover[2] خودکار) و از تکنیک sharding خودکار جهت مقیاس پذیری افقی و توزیع اسناد در میان سرویسدهندهها، استفاده میشود، بنابراین، هم عمل خواندن و هم عمل نوشتن، مقیاسپذیر است(یعنی هر گرهای میتواند به درخواستهای خواندن و نوشتن پاسخ دهد).در مقابل، در CouchDB از تکنیک تکثیر جهت مقیاسپذیری استفاده میشود و sharding بصورت خودکار انجام نمیشود.
- mongoDB از پرسوجوهای پویا بهمراه استفاده خودکار از اندیسها پشتیبانی میشود (مانند RDBMSها).
- mongoDB دادهها را در فرمت JSON دودویی که BSON نام دارد ذخیره و در اتصال سوکت به سرویسدهنده mongoDB ارسال میکند. در مقابل، couchDB، فایل JSON را بصورت متنی توسط واسط REST ارسال میکند.
بررسی MongoDB از دید برنامه نویسی توزیع شده
همچنین، در mongoDB میتوان از مدل برنامه نویسی توزیع شده ی نگاشت-کاهش جهت اجرای توابع تجمعی[3] پیچیده استفاده کرد. در زیر نمونه ای از سند mongoDB مشاهده میشود:
{ “_id” : ObjectId(“54c955492b7c8eb21818bd09”), “address” : { “street” : “2 Avenue”, “zipcode” : “10075”, “building” : “1480”, “coord” : [ -73.9557413, 40.7720266 ] }, “borough” : “Manhattan”, “cuisine” : “Italian”, “grades” : [ { “date” : ISODate(“2014-10-01T00:00:00Z”), “grade” : “A”, “score” : 11 } ], “name” : “Vella”, “restaurant_id” : “41704620”
}
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 4414
برچسبDocument Store MongoDB بررسی MongoDB بررسی مانگو دی بی درآمدی MongoDB سند گرا مانگو مبتنی بر سند نقاط ضعف مانگو دی بی ویژگیهای مخصوص مانگو
نوشته های مرتبط






همچنین ببینید

پایگاه داده BigchainDB معماری و نحوه عملکرد آن
پایگاه داده BigchainDB نرم افزاری است که دارای خصوصیات blockchain (به عنوان مثال عدم تمرکز …

واحدهای داده ای در پایگاه داده ی مانگو (MongoDB)
مدل واحدهای داده ای در MongoDB: بلعکس پایگاه داده های رابطه ای که همگی از …
