 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
ایندکس معکوس (inverted index) چیست؟
در قسمت های قبل روشهای شاخص گذاری بر روی داده ها را بررسی نمودیم. اکنون در بخش ایندکس معکوس (inverted index) مورد مطالعه قرار میدهیم. شاخص گذاري معکوس، يک مکانيزم مبتني بر کلمه است که براي جستجوي سريع اسناد شامل يک کلمه خاص به کار ميرود. در اينجا منظور از سند، دنباله محدودي از کاراکترها است و يک کلمه، زيردنبالهاي از يک سند است.
شاخص گذاري معکوس داراي دو مولفه اصلي است:
- کلمه
- ليستی از کلمه ها
يک “ليست پست” (Posting list) که در ارتباط با يک کلمه ي خاص است، اطلاعاتي را درباره رخدادهاي کلمه نگهداري ميکند و شامل شناسه سند (کلمه و ليست مکانهاي کلمه در آن سند) است. در شکل های زیر فرایند و مراحل نمایه گذاری معکوس نمایش داده شده است.
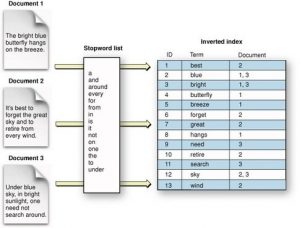
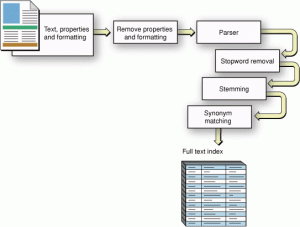
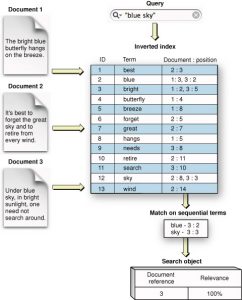
براي هر کلمه ، ليست پست شامل پستهاي <d,[o1,…,of]> است که در آن d شناسه سند، [o1,…,of] ليست مکان ها و f تعداد تکرارهاي کلمه در سند d است. گذشته از اينها، شاخصگذاري+ B-tree نيز بر روي کلمه ها اعمال ميشود تا به سرعت يک ليست پست را مکانيابي کند. شکل زیر ساختار شاخص معکوس را نشان ميدهد.
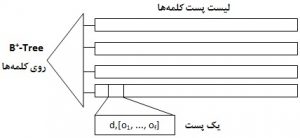
ساختار ایندکس معکوس (شاخص معکوس)
با توجه به روش استخراج کلمه ها، شاخصگذاري معکوس به دو قسمت طبقه بندي ميشود:
1) شاخص گذاري معکوس بر مبناي انتخاب کلمه که خود بر دو نوع بوده و در ادامه توضيح داده ميشود
2) شاخصگذاري چند-وزني، که بيشتر روي شاخص گذاري چند-وزني تمرکز ميشود.
انواع شاخص گداری یا ایندکس معکوس بر مبناي انتخاب کلمه عبارتند از:
شاخصگذاري مبتني بر کلمه
روش شاخصگذاري مبتني بر کلمه (Word-Based Indexing) در زبانهاي زيادي همانند انگليسي و اسپانيايي استفاده ميشود تا اسناد و پرس و جوها را نمايش دهد. شاخصگذاري مبتني بر کلمه، کلمات را با بعضي نشانهها همانند فضاهاي خالي و ویرگول از هم تفکيک ميکند. همچنين شامل فرآيند ريشهيابي می باشد. در فرآیند ریشهیابی اضافات انتهاي کلمات را عموماً حذف ميکند تا کلاسهاي مشابه براي شکلهاي مختلف کلمات يافت شود. براي مثال، ريشهياب، براي واژههاي «مهندسي کردن»، «مهندسي» و «مهندس» واژه شاخص «مهندس» را توليد ميکند. اين روش شاخصگذاري، ريشهيابي را انجام داده و واژههاي شاخص را با استفاده از تغيير شکل متن به صورت زير توليد ميکند:
- شناسايي کلمات مجزا در متن
- توليد ريشههاي کلمات با استفاده از حذف پسوندها
- حذف ريشههاي کلماتي که متعلق به ليست توقف هستند.
اين روش، يک اسم ترکيبي را به اسامي سادهتر تجزيه نميکند و زمانيکه متن شامل تعداد زيادي اسم ترکيبي باشد، کارايي بازيابي اطلاعات به طور جدي کاهش مييابد.
شاخصگذاري مبتني بر کوچکترين واحد زبان
روش شاخصگذاري مبتني بر کوچکترين واحد زبان (Morpheme-Based Indexing) مشکل شاخصگذاري مبتني بر کلمه (عدم تجزيهي اسامي مرکب به اسامي سادهتر) را ندارد، زيرا اسناد و پرس و جوها را تنها با اسامي ساده نشان ميدهد. معمولاً روش شاخصگذاري مبتني بر کوچکترين واحد زبان شامل 5 گام است:
- شناسايي کلمات مجزا در متن
- جداسازي يک کلمه به شکل تمامي دنبالههاي ممکن از اجزاي زبان
- انتخاب محتملترين دنباله از اجزاي زبان
- استخراج اسامي ساده از دنباله
- حذف اسامي ساده متعلق به ليست توقف
در اين روش از شاخصگذاري، سطوحي از پردازش زبان طبيعي که شامل تحليل لغوي يا تحليل معنايي هستند، پوشش داده ميشوند و يک کلمه به شکل يک مجموعه از کوچکترين واحدهاي معنيدار زبان که اغلب واژک ناميده ميشود، تجزيه ميشود و شاخههاي لغوي آن را که شامل اسامي ساده، فعلها، صفتها و واژههاي ناشناخته هستند، توليد ميکند. بنابراين تنها اسامي ساده را به عنوان کلمات کليدي بازيابي و استخراج ميکند.
شاخصگذاري چند-وزني
کاربرد چند-وزنيها براي بازيابي اطلاعات از تمايل براي کاهش اندازه مجموعه لغات (Dictionary) ناشي ميشود . تعداد کلماتي که ممکن است در يک مجموعه يافت شوند، محدود به n (تعداد حروف الفبا) است. براي مثال، زماني که زبان انگليسي مدنظر باشد و n=3 در نظر گرفته شود، با توجه به اينکه تعداد حروف انگليسي 26 است، در نتيجه حداکثر 19683 عدد 3-وزني ممکن است يافت شود. بر اين اساس، مطالعات بيشماري روي تاثير چند-وزنيها انجام شده است. در سال 1974،de hear استفاده از چند-وزنيها را به عنوان جايگزيني براي کلمات، کشف کرد. او مجموعهاي از چند-وزنيهايي که از يک کلمه مشتق ميشوند، دنباله نحوي (syntactic trace) آن کلمه ناميد. کارهاي بعدي به تدريج طول چند-وزني را افزايش دادند که طول چند-وزنيها با تغيير بسامد واژه و افزايش اندازه مجموعه آزمايشي تغيير ميکند. در سال 1990 ميلادي، تغييراتي در چگونگي ايجاد چند-وزنيها هنگام بازيابي اطلاعات رخ داد. اين تغييرات شامل افزايش n و جابجايي چند-وزنيها بود. از لحاظ کيفي، اين تغييرات، ديدگاه جديدي از چند-وزنيها را با عنوان کلمههاي شاخصگذاري منعکس کرد که از به کارگيري نمايش نادرستي از کلمات اجتناب میکرد. علاوه بر تاثير چند-وزنيها بر روي کلمههاي شاخصگذاري (کاهش مصرف حافظه)، اهميت متمايز و ممتاز ديگر آن، شباهتيابي اسناد است (صحت بازيابي). کاربردهاي چند-وزني علاوه بر بازيابي اسناد، شناسايي زبان، تشخيص خطاي املايي و برجستهسازي کلمات کليدي است. همچنين بزرگترين کاربرد چند-وزنيها، در بازيابي اطلاعات زبانهاي آسيايي است. اين روش، واژههاي شاخص را با استفاده از تبديل متن، به صورت زير توليد ميکند:
- شناسايي کلمات مجزاي متن
- توليد ريشههاي کلمات با استفاده از حذف پسوندها
- حذف ريشههاي کلمات متعلق به ليست توقف
- شکستن ريشههاي کلمات باقيمانده به شکل چند-وزني
چند-وزنيها را ميتوان به دو شاخه تقسيم کرد:
1) چند-وزني بر اساس حرف
2) چند-وزني بر اساس کلمه
منبع:
م. دانش، “يک سامانه شاخص گذاري چند-وزني توزيع شده براي بهبود بازيابي اطلاعات در زبان فارسی”، پاياننامه کارشناسي ارشد، کتابخانه دانشگاه علم و صنعت، 1390
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 7767
برچسبB-tree Index inverted index اندیس ایندکس معکوس اینورتد ایندکس چند-وزني بر اساس حرف چند-وزني بر اساس کلمه شاخص گذاری شاخص گذاری معکوس شاخص معکوس شاخصگذاري چند وزني شاخصگذاري مبتني بر کلمه شاخصگذاري مبتني بر کوچکترين واحد زبان نمایه
نوشته های مرتبط













همچنین ببینید

محصولات و تکنولوژی های آپاچی (Apache) در حوزه کلان داده و داده کاوی
یکی از موسسات مطرح در زمینه پشتیبانی از داده های حجیم، بنیاد آپاچی می باشد. …
انواع ایندکس یا اندیس در پايگاه داده (Index)
انواع ایندکس: از اندیسها میتوان برای بهبود عملکرد پایگاهداده استفاده کرد. اندیسها به سرویسدهنده پایگاهداده …
یک دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

خیلی عالی بود، تشکر