خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
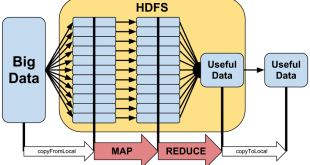
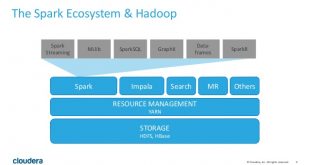
نصب، راه اندازی و پیکربندی اسپارک (Spark) در لینوکس
در این پست نصب، راه اندازی و پیکربندی چارچوب apache spark 1.3.1 یکپارچه با hadoop yarn بررسی خواهیم کرد.
مرحله ۱. نصب OpenJDK1.7- نحوه نصب بسته توسعه جاوا در پست نصب جاوا (jdk) در لینوکس بطور مفصل توضیح داده شد.
تکته بسیار مهم: توجه داشته باشید که در اجرای این نسخه از spark بر روی hadoop yarn 1.5.1 و با Oracle java 8 نصب شده در سیستم، به مشکل بر خورد کردم. اما این نسخه از Spark با نسخه ۸ جاوا نصب شده در سیستم، بدون هیچ مشکلی بصورت local اجرا شد. در نتیجه برای اینکه Spark بدون هیچ مشکلی قابل اجرا بر روی Yarn باشد، حتماً jdk 1.7 (java 7) را نصب کنید.
مرحله ۲. دانلود Spark-1.3.1-bin-hadoop2.4- برای اینکه Spark بر روی هادوپ و مدیر منابع Yarn قابل اجرا باشد و بتوان برنامههای Spark را بر روی کلاسترهای هادوپ اجرا و از HDFS به عنوان مخزن داده استفاده کرد، باید نسخه Spark-1.3.1-bin-hadoop2.4 را دانلود کنیم.
بدین منظور به صفحه دانلود spark در مسیر http://spark.apache.org/downloads.html بروید، و پس از انتخاب نسخه spark و نوع بسته spark ( بر اساس نسخه هادوپ نصب شده در سیستم، برای نمونه Spark-1.3.1-bin-hadoop2.4 ) را انتخاب کنید. سپس در مرحله چهار در همین صفحه دانلود، بر روی لینک کلیک و بسته فشرده tgz را دانلود کنید.
مرحله ۳.نصب– ابتدا بسته دانلود شده را با دستور tar -xzvf از حالت فشرده خارج کنید و سپس متغیر محیطی SPARK_HOME را برابر با مسیر spark قرار دهید.
$ cd ~/Downloads
$ tar -xvzf spark-1.3.1-bin-hadoop2.4.tgz
$ mv spark-1.3.1-bin-hadoop2.4 ~/
$ nano ~/.bashrc
export SPARK_HOME=/home/mahdi/spark-1.3.1-bin-hadoop2.4
مرحله ۴. پیکربندی اسپارک– برای اینکه اسپارک، هادوپ نصب شده در سیستم را درک کند باید مسیر فایلهای پیکربندی yarn و hdfs را بداند:
$ cd $SPARK_HOME/conf
$ nano spark-env.sh
export HADOOP_CONF_DIR=/home/mahdi/hadoop-2.5.2/etc/hadoop
همانطور که مشاهده میکنید، متغیر HADOOP_CONF_DIR را تعیین کردیم. شما هم باید این متغیر را برابر مسیر فایلهای پیکربندی هادوپ نصب شده در سیستم تان قرار دهید.
مرحله ۵. اجرای محیط تعاملی spark-shell- برای اجرای دستورات تعاملی اسپارک، میتوانید در spark-shell بصورت تعاملی، دستورات اسپارک را اجرا کنید:
اجرا بصورت محلی (با نخ های ماشینی که این دستور بر روی آن اجرا می شود):
$ cd $SPARK_HOME
$ bin/spark-shell
اجرا در Yarn:
$ cd $SPARK_HOME
$ bin/spark-shell –master yarn
در هر دو حالت، پس از اینکه خط فرمان به scala> تبدیل شد، اگر اجرای sc (متغیر راه انداز که اسپارک خودش میسازد) مقداری را بر گرداند، یعنی تمام مراحل با موفقیت انجام شده است.
scala> sc
res1: org.apache.spark.SparkContext = org.apache.spark.SparkContext@6999a897
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 2755
برچسبSpark اسپارک نصب اسپارک در لینوکس نصب و راه اندازی