 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آموزش کامل TSQL و دستورات پایگاه داده های SQL Server ، MySQL و Oracel
SQL یا (Structured Query Language) يک زبان ساخت يافته برای ثبت، بازيابی و بهنگام سازی داده از يک پايگاه داده رابطه ای و حتی پایگاه داده های غیر رابطه ای است. دستوراتی برای ايجاد، حذف و تغيير اشيای مختلف در پايگاه داده دارد. پرکاربرد ترين دستور آن برای اجرای پرس و جوهای مختلف روی پايگاه داده استفاده می شود. SQL يک زبان برنامه نويسی تعاملی استاندارد برای بازيابی و بهنگام سازی پايگاه داده رابطه ای است. SQL امکان ايجاد جدول، اضافه و حذف داده، اصلاح داده و اجرای پرس و جوی روی داده به شکل يک زبان فرمانی فراهم می کند. SQL به عنوان يک استاندارد توسط ANSI در سال 1986 و توسط ISO در سال 1987 پذيرفته شد. در اين بخش فرامينی از SQL که در اکثر گونه های DBMS وجود دارد شرح داده خواهد شد. و از آنجایی که در این کتاب برای یک دست شدن مثال ها از محصولات میکروسافت استفاده می کنیم لذا برای بیشتر مثال های این بخش هم پایگاه داده MS SQL Server را ملاک کار خود قرار می دهیم. حال به تعریف اولیه به چند واژۀ پر کاربرد در SQL می پردازیم :
عناوين مطالب: '
مروری بر دستوراتTSQL و پایگاه داده های رابطه ای
SQL یا (Structured Query Language) يک زبان ساخت يافته برای ثبت، بازيابی و بهنگام سازی داده از يک پايگاه داده رابطه ای و حتی پایگاه داده های غیر رابطه ای است. دستوراتی برای ايجاد، حذف و تغيير اشيای مختلف در پايگاه داده دارد. پرکاربرد ترين دستور آن برای اجرای پرس و جوهای مختلف روی پايگاه داده استفاده می شود. SQL يک زبان برنامه نويسی تعاملی استاندارد برای بازيابی و بهنگام سازی پايگاه داده رابطه ای است. SQL امکان ايجاد جدول، اضافه و حذف داده، اصلاح داده و اجرای پرس و جوی روی داده به شکل يک زبان فرمانی فراهم می کند. SQL به عنوان يک استاندارد توسط ANSI در سال 1986 و توسط ISO در سال 1987 پذيرفته شد. در اين بخش فرامينی از SQL که در اکثر گونه های DBMS وجود دارد شرح داده خواهد شد. و از آنجایی که در این کتاب برای یک دست شدن مثال ها از محصولات میکروسافت استفاده می کنیم لذا برای بیشتر مثال های این بخش هم پایگاه داده MS SQL Server را ملاک کار خود قرار می دهیم. حال به تعریف اولیه به چند واژۀ پر کاربرد در SQL می پردازیم :
Query: به معنای درخواست است و در sql به کد جستجویی می گویند که شما برای بدست آوردن نتیجه ای آن را مینویسید و اجرا می کنید .
Resault set: نتیجه بدست آمده از یک Query را میگویند.
نکته: فضاهای خالی در عبارات SQL نديده گرفته می شوند و برای خوانائی کدهای SQL استفاده می شوند و سميکولن (;) به عنوان پايان دهنده عبارت است.
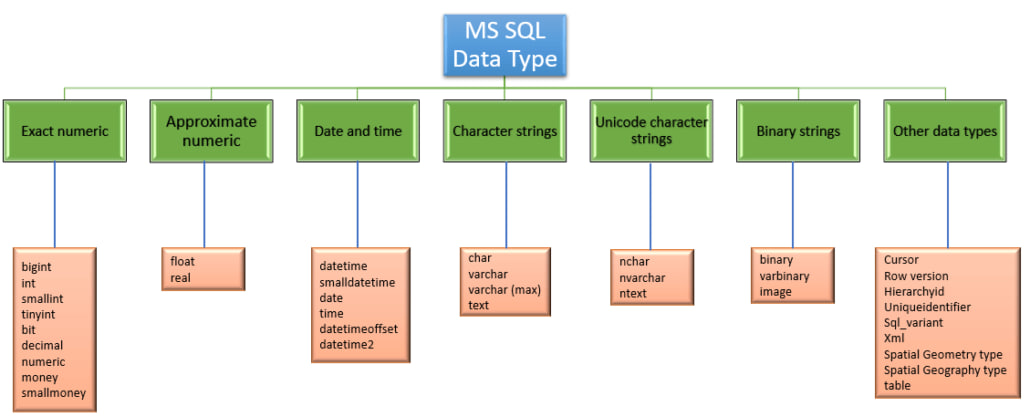
برای ساخت جدول باید ابتدا فیلدها یا همان ستونهای جدول تعریف شود. فیلدهای دارای DataType های مختلفی هستند كه آنها را به اختصار توضیح می دهیم.
انواع داده ها
|
شرح داده |
نوع داده |
|
این نوع فیلدها برای نگهداری اطلاعات به صورت باینری مانند تصاویر مناسب هستند و شامل چهار نوع به شرح زیر میباشد |
Binary Data |
|
این نوع فیلدها، از 1 تا 8000 بایت را در خود جای میدهند |
Binary |
|
این نوع فیلدها هم از 1 تا 8000 بایت را در خود جای میدهند. (متغیر) |
Var Binary |
|
این نوع فیلدها از 1 تا حداكثر 2 گیگابایت را میتوانند ذخیره كنند. فرق این نوع دادهها با دو نوع قبلی این است كه در دو نوع قبلی، اطلاعات در خود ركورد ثبت میشوند ولی در این نوع دادهها، اطلاعات در یك Page ذخیره میشود و به جایش در ركورد، یك پوینتر 16 بایتی ذخیره میشود. این نوع فیلدها در SQL 10 حذف شده و به جایش باید از VarBinary استفاده كرد. |
Image |
|
این نوع Datatype در SQL 2005 معرفی شده و تقریباً همانند دادههای Image هستند |
VarBinary(Max) |
|
این نوع فیلد برای نگهداری عبارات و یا حروف ASCII میباشد. در این نوع فیلدها، برای نگهداری هر حرف، یك بایت اشغال میشود و لذا نیاز به Collation برای تعیین زبان اطلاعات میباشد. این نوع فیلدها هم چهار نوع هستند |
Character Data |
|
این نوع فیلدها، اطلاعات متنی (رشته کاراکتری ASCII) با طول ثابت از 1 تا حداكثر 8000 حرف را در خود ذخیره میكنند. |
Char |
|
این نوع فیلدها اطلاعات متنی (رشته کاراکتری Unicode) با طول متغیر از 1 تا حداكثر 8000 حرف را در خود ذخیره میكنند. فرق بین Char و VarChar در این است كه در Char، طول رشته ثابت است. یعنی اگر یك فیلد را از نوع Char(20) معرفی كرده و در آن كلمه Orion را قرار دهیم، عین 20 حرف استفاده خواهد شد. یعنی 5 كاراكتر اول را كلمه مربوطه اشغال كرده و 15 كاراكتر باقیمانده، Blank خواهند بود. اما در VarChar اینگونه نیست. |
VarChar |
|
: در این نوع دادهها، اطلاعات از 1 تا 2 مگا حرف ذخیره میشود. این نوع داده همانند Image و VarBinary(MAX) در خود ركورد ذخیره نمیشوند. بلكه توسط یك پوینتر به جای دیگری اشاره میكنند. این نوع داده در SQL 10 حذف شده و بجای آنها از VarChar(MAX) استفاده میشود |
Text |
|
در این نوع دادهها، اطلاعات از 1 تا 2 مگا حرف ذخیره میشود و مكانیزم آن هم بصورت پوینتری میباشد. |
VarChar(Max) |
|
این نوع فیلدها برای نگهداری متون Unicode بوده و برای نگهداری هر حرف، از دو بایت استفاده میشود. پس مسلماً نسبت به نوع دادههای كاراكتری، حافظه بیشتری را به خود اختصاص میدهد و در ضمن كمی هم كندتر است. این نوع فیلدها، احتیاج به Collation ندارند. |
Unicode Data |
|
در این نوع داده، اطلاعات از 1 تا حداكثر 4000 حرف با طول ثابت ذخیره میشود |
nChar |
|
در این نوع داده، اطلاعات از 1 تا حداكثر 4000 بایت با طول متغیر ذخیره میشود |
nVarChar |
|
در این نوع داده، از 1 تا 1 مگا حرف ذخیره میشود. مكانیزم آن هم بصورت Pointer میباشد |
nText |
|
در این نوع داده از 1 تا 1 مگا حرف ذخیره میشود. مكانیزم آن هم بصورت Pointer میباشد |
nVarChar(MAX) |
|
این نوع فیلد برای نگهداری اعداد صحیح و بدون اعشار استفاده میگردد و دارای 4 نوع به شرح زیر است. در ضمن این نوع فیلدها رتبه یك سرعت در نوع فیلدهای عددی را دارد. |
Integer Data |
|
یك بایت را اشغال میكند و میتواند از 0 تا 255 را در خود ذخیره كند |
TinyInt |
|
یك عدد دو بایتی است و میتواند از 32767 منفی تا 32767 مثبت را در خود ذخیره كند |
SmallInt |
|
یك عدد چهار بایتی است كه میتواند اعداد بین مثبت و منفی 2 میلیارد را در خود ذخیره كند |
Int |
|
یك عدد 8 بایتی است كه میتواند اعداد بین مثبت و منفی 4 میلیارد را در خود ذخیره كند |
BigInt |
|
این نوع فیلد برای نگهداری اعداد غیر صحیح با تعداد ارقام اعشار ثابت 4 رقمی استفاده میشود. این نوع فیلدها، دارای رتبه دوم سرعت در بین انواع دادهی عددی است. |
Money Data |
|
یك عدد 4 بایتی است كه میتواند 6 رقم صحیح و 4 رقم اعشار را در خود ذخیره كند |
SmallMoney |
|
: یك عدد 8 بایتی است كه میتواند 15 رقم صحیح و 4 رقم اعشار را در خود ذخیره كند |
Money |
|
این نوع فیلدها برای نگهداری اعداد غیر صحیح با تعداد ارقام اعشار متغیر و یا تخمـینـی استفاده میشود. این نوع دادهها رتبه سوم سرعت در بین انواع دادههای عددی دارند و استفاده از آنها به دلیل كندی، توصیه نمیگردد. |
Approximate Data |
|
یك عدد 4 بایتی است كه اعداد بصورت توانی از 10 نگهداری میشوند. (تعداد اعشار مشخص نیست |
Real |
|
یك عدد 8 بایتی كه اعداد بصورت توانی از 10 نگهداری میشوند. (تعداد اعشار مشخص نیست |
Float |
|
این نوع فیلد برای نگهداری اعداد اعشاری با تعداد اعشار مشخص استفاده میگردد. این نوع فیلدها بسیار كند بوده و استفاده از آنها توصیه نمیگردد. فرمت اینگونه دادهها به این شكل است: Decimal (Precision,Scale)كه در آن Precision به معنای تعداد كل رقمهای عدد و Scale تعداد ارقام اعشار را مشخص میكند. مثلاً اگر فیلدری بصورت Deciaml(6,2) تعریف شود، حداكثر آن برابر 9999.99 میباشد. |
Decimal |
|
این نوع فیلدها برای نگهداری تاریخ میلادی و ساعت استفاده میشود و برای تاریخ شمسی كاربرد ندارد |
Date/Time |
|
این نوع فیلد، 4 بایتی است و از سال 1900 تا 2079 را با دقت هزارم ثانیه ذخیره میكند |
SmallDateTime |
|
: این نوع فیلد، 8 بایتی است و از سال 1700 تا 9999 را با دقت هزارم ثانیه ذخیره میكند |
DateTime |
|
برخی از انواع فیلدهای خاص را در این قسمت به اختصار توضیح می دهیم |
Other DataTypes |
|
یك فیلد دو بیتی است و میتواند 0 و 1 و Null را ذخیره كند.كاربرد آن در زمانهایی است كه دو حالت وجود داشته باشد. مانند جنسیت زن و مرد |
Bit |
|
در این فیلد 8 بایتی، تایم لحظهای اجرای دستور نگهداری میشود و كاربرد آن كنترل بروزرسانی همزمان (Concurrency) اطلاعات توسط چند كاربر است. البته در تعداد ركوردهای پایین به كار نمیآید و بیشتر زمانی مورد نیاز است كه تعداد ركوردها خیلی زیاد باشد مثلاً 100 میلیون ركورد! |
TimeStamp |
|
این فیلد 16 بایتی، به ما كدی Unique یا تك میدهد كه به اصطلاح GUID میگویند. یكی از كاربردهای آن در Replication است |
UniqueIdentifier |
|
: این نوع فیلد برای نگهداری انواع داده استفاده میشود و نوع آن با توجه به اولین مقداری كه در آن قرار میگیرد تعیین خواهد شد. چون نوع و حجم فیلد مشخص نیست، لذا تنها یك اشارهگر 16 بایتی در آن قرار گرفته و داده اصلی در فایل جداگانه نگهداری میشود. استفاده از این نوع فیلد، توصیه نمیگردد |
SQL_Variant |
|
این فیلد مربوط به كنترل Cursor است |
Cursor |
|
این فیلد بیشتر برای انتقال اطلاعات و دستورات تحت web استفاده میشود و شامل انواع MetaData های مختلف است. این فیلد در SQL 2005 معرفی گردید |
XML |
خواص تکمیلی فیلد ها
PRIMARY KEY : يعنی اين فيلد از نوع کليد اصلی است.
NOT NULL: يعنی اين فيلد بايد مقداری داشته باشد و نمی تواند تهی باشد.
:REFERENCES othertable (primarykeyname) يعنی اين فيلد يک کليد خارجی است که در جدول ديگری کليد اصلی است.
در انتهای تعريف می توان اطلاعات اضافی ديگری را داشت. برای نمونه:
PRIMARY KEY (column1,column2,…): اگر جدول کليد اصلی ترکيبی دارد بايد آنرا در انتهای تعريف مشخص کنيد.
FOREIGN KEY (column1,column2,…) :REFERENCES othertable اگر جدول ارتباطی با جدول ديگر دارد که يک کليد ترکيبی دارد بنابراين ستون های اين جدول که کليد های خارجی هستند بايد به اين صورت ليست شوند.
انواع دستورات SQL
دستورات DML و DDL در اس کیو ال
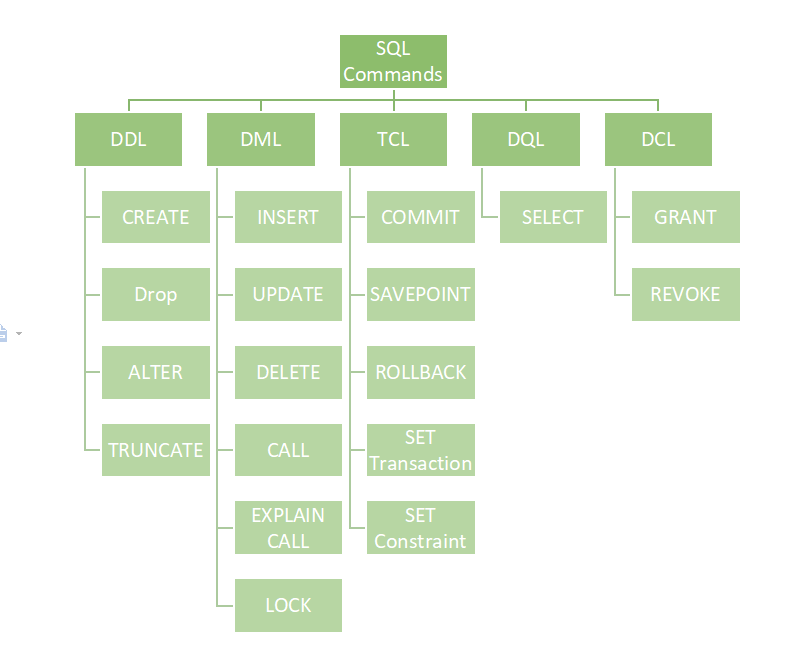
SQL به دو قسمت تقسیم میشود :
- زبان دستکاری داده ها DML (Data Manipulation Language)
- زبان تعریف داده ها DDL (Data Definition Language)
دستورات DML شامل بخشهای زیر میشوند
- SELECT واکشی اطلاعات از دیتابیس
- UPDATE ویرایش اطلاعات دیتابیس
- DELETE پاک کردن اطلاعات از دیتابیس
- INSERT INTO اضافه کردن اطلاعات جدید به دیتابیس
دستورات DDLشامل بخشهای زیر میشوند
- CREATE DATABASE ایجاد یک دیتابیس جدید
- ALTER DATABASE ایجاد تغییرات در دیتابیس
- CREATE TABLE ایجاد یک table جدید
- ALTER TABLE اعمال تغییرات در table
- DROP TABLE پاک کردن یک table
- CREATE INDEX ایجاد یک شاخصه
- DROP INDEX حذف یک شاخص
CREATE TABLE
عبارت Create يک فرمان [1]DDL در SQL است که برای ايجاد يک شیء در پايگاه داده استفاده می شود. احتمالا معمول ترين فرمان Create فرمان CREATE TABLE است. این اجازه ايجاد شمای يک جدول را می دهد. فرم کلی آن به صورت زير است:
CREATE TABLE tablename (
colname datatype coloptions
,colname datatype coloptions
,colname datatype coloptions
,additionalinfo
);
هر سطر يک فيلد جدول را مشخص می کند. تعريف هر فيلد شامل نام، نوع داده و اطلاعات اضافی مربوطبه آن می تواند باشد. سطرها با کاما (,) از هم جدا می شوند.
مثال: تعريف جداول Car و Driver با چند فيلد نمونه می تواند به صورت زير باشد:
CREATE TABLE driver (
name varchar(30)
,dob DATE NOT NULL
,PRIMARY KEY (name)
);
CREATE TABLE car (
regno VARCHAR(8)
,make VARCHAR(20)
,colour VARCHAR(30)
,price DECIMAL(8,2)
,owner VARCHAR(30)
,PRIMARY KEY(regno)
,FOREIGN KEY(owner) REFERENCES driver
);
DROP TABLE
عبارت DROP برای از بين بردن يک شیء در پايگاه داده است. فرمان DROP TABLE زمانی بکار می رود که بخواهيد جدول را حذف کنيد. فرم کلی آن به صورت زير است:
DROP TABLE tablename;
مثال. فرمان زير جدول car را حذف می کند.
DROP TABLE car;
تنها نکته در حذف يک جدول اين است که اگر جدولی توسط کليد خارجی با اين جدول در ارتباط باشد نمی توانيد آنرا حذف کنيد.
مثال. چون جدول car توسط کليد خارجی با جدول driver در ارتباط است می توانيد ابتدا جدول Car و سپس Driver را حذف کنيد ولی عکس آن نمی شود.
DROP TABLE car;
DROP TABLE driver;
SELECT
معمولا بيشترين عملی که روی پايگاه های داده توسط SQL انجام می گيرد جستجو است، که توسط عبارت SELECT انجام می پذيرد. دستور SELECT داده ها را از يک يا چند جدول مرتبط بازيابی می کند و اغلب تاثيری روی داده ذخيره شده در پايگاه داده ندارد. SELECT پيچيده ترين عبارت SQL است. فرم کلی عبارت SELECT به صورت زير است:
SELECT DISTINCT columns AS columns
FROM table
WHERE rule
GROUP BY columns
HAVING rule
ORDER BY columns;
دستور SELECT دارای چند عبارت اختياری به شرح زير است:
• FROM جدول يا جداولی را که از آنها داده بازيابی می شود را مشخص می کند. برای الحاق جداول بر اساس ضابطه خاصی می تواند همراه با عبارت JOIN بيايد.
• WHERE همراه با يک گزاره شرطی برای محدود کردن سطرهای برگردانده شده استفاده می شود.
• GROUP BY اغلب همراه با توابع تجمعی(AVE، SUM، MAX، MIN و COUNT) برای ترکيب يا گروه بندی سطرها يا حذف سطرهای تکراری در مجموعه نتيجه استفاده می شود.
• HAVING همراه با يک گزاره شرطی روی نتيجه GROUP BY کار می کند. توابع تجمعی می توانند در گزاره شرطی HAVING هم استفاده شوند.
• ORDER BY برای تعيين ستون های که بر اساس آنها داده نتيجه مرتب می شود (صعودی و نزولی) .
FROM
در ساده ترين دستور SELECT کليه سطرهای يک جدول که بعد از عبارت FROM ذکر شده است را بازيابی می کند. ليستی از فيلدهای موردنظر در مقابل عبارت SELECT قرار می گيرد. نام فيلدها با کاما (,) از هم جدا می شوند. علامت ستاره (*) برای بيان کليه فيلدهای يک جدول (يا چند جدول) می تواند استفاده شود.
مثال. اسامی کليه شعبه ها در loan را پيدا کن
SELECT branch_name
FROM loan;
مثال. مشخصات کليه مشتريان را پيدا کن.
SELECT *
FROM customer;
عبارات محاسباتی +، – ، * و / روی يک فيلد در ليست فيلدها می توانند بکاربرده شوند.
مثال. دستور زير جدولی مشابه loan را بر می گرداند که مقدار صفت خاصه amount آن 10 برابر شده است.
SELECT loan_number, branch_name, amount * 10
FROM loan;
ممکن است لازم باشد داده های مورد نياز را از دو يا چند يک جدول استخراج کنيم.
مثال. اسامی و مقدار وام کليه مشتريانی را که وامی از شعبه Perryridge گرفته اند را پيدا کن.
SELECT customer_name, borrower.loan_number, amount
FROM borrower, loan
WHERE borrower.loan_number = loan.loan_number AND
branch_name = ‘Perryridge’;
مثال. دقت کنيد که اگر شرطی ذکر نشود ضرب دکارتی دو جدول حاصل می شود.
SELECT *
FROM borrower, loan;
DISTINCT
SQL اجازه تکرار در نتيجه SELECT را می دهد. بنابراين جدول حاصل ممکن است دارای سطرهای مشابه باشد. اگر اين موضوع موردنظر نباشد عبارت DISTINCT را استفاده می کنيم. در اين صورت کليه سطرهای جدول حاصل منحصر بفرد خواهند بود. و سطرهای تکراری حذف می شوند.
مثال. اسامی کليه شعب بانک که از آنها وامی گرفته شده است را با حذف تکراری ها ليست کن.
SELECT DISTINCT branch_name
FROM loan;
عبارت all مشخص می کند که تکراری ها حذف نشوند.
SELECT ALL branch_name
FROM loan;
WHERE
عبارت WHERE برای انتخاب سطرهای برگردانده شده از دستور SELECT بر طبق شرط خاصی بکار می رود.
برای بيان شرط می توان عملگرهای مقايسه ای (=، !=، <>، >، <، >= و <=) را استفاده کرد.
نتايج مقايسه را می توان توسط عملگرهای منطقی (NOT، AND و OR ) و پرانتز با هم ترکيب کرد. اجرای عملگرهای منطقی به ترتيب الويت آنها است. NOT الويت بالاتر و OR الويت کمتر را دارد. پرانتز می تواند برای تعيين ترتيب انجام عمليات استفاده شود. عمل داخل پرانتز هميشه اول انجام می گيرد.
مثال. کليه شماره وام هائی که مقدار وام آنها از 1200 بيشتر است را پيدا کن.
SELECT loan_number
FROM loan
WHERE amount > 1200;
مثال. کليه شماره وام های شعبه Perryridge که مقدار وام آنها از 1200 بيشتر است را پيدا کن.
SELECT loan_number
FROM loan
WHERE amount > 1200 AND branch_name = ‘Perryridge’;
توجه کنيد که هنگام مقايسه با رشته بايد آنرا در کوتيشن (‘ ‘) قرار داد.
مثال.شماره وام هائی که مقدار وام آنها بين 90,000 و 100,000 می باشد را پيدا کن.
SELECT loan_number
FROM loan
WHERE amount BETWEEN 90000 AND 100000;
عملگر IN برای تعيين اينکه آيا مقدار مشخصی درون مجموعه ای از مقادير وجود دارد يا خير بکار می رود.
مثال. مقدار وامهايی که از شعب Perryridge، Downtown يا Redwood گرفته شده اند را پيدا کن.
SELECT amount
FROM loan
WHERE Branch_name IN (‘ Perryridge’ , ‘Downtown’ , ‘Redwood’);
هنگام کارکردن با رشته ها وقتی خواهان مطابقت کامل رشته ها نيستيم بلکه بخشی از رشته يا الگوی خاصی از آن بيشتر موردنظر است، می توان از عبارت LIKE به جای علامت (=) استفاده کرد. دو کاراکتر ‘%’ و ‘_’ به ترتيب به معنی يک کاراکتر و بيشتر از يک کاراکتر را برای تطابق می توان بکار برد.
مثال. اسامی کليه مشتريانی که آدرس آنها شامل کلمه Main است را پيدا کن.
SELECT customer_name
FROM customer
WHERE customer_street LIKE ‘%Main%’;
AS
SQL اجازه تغيير نام جدول را توسط عبارت AS می دهد.
مثال. تعداد وام و مقدار وام کليه وام ها را پيدا کرده، نام ستون loan_number به loan_id تغيير بده.
SELECT loan_number AS loan_id, amount
FROM loan;
مثال. نام و تعداد وام کليه مشتريانی که وامی در يک شعبه دارند را پيدا کن.
SELECT customer_name, T.loan_number, S.amount
FROM borrower AS T, loan AS S
WHERE T.loan_number = S.loan_numbe;
توابع تجمعی
توابع تجمعی (aggregation function) عملگرهايی هستند که محاسبه آماری روی گروهی از مقادير داده ای را انجام می دهند. اين توابع روی مقادير يک ستون از يک جدول عمل می کند و يک مقدار را به عنوان نتيجه بر می گردانند. اين توابع شامل AVG، SUM، MAX، MIN و COUNT هستند.
نتيجه تجمع نامی ندارد می تواند از AS برای نامگذاری آن استفاده کرد.
مثال. ميانگين موجودی حساب ها در شعبه Perryridge را پيدا کن.
SELECT AVG (balance)
FROM account
WHERE branch_name = ‘Perryridge’;
COUNT تعداد سطرهای موجود در جواب که حاوی NULL نيستند را می دهد. برای اينکه تعداد مستقل از NULL باشد COUNT(*) را استفاده کنيد.
مثال. تعداد مشتريان بانک را محاسبه کن.
SELECT COUNT (*)
FROM customer;
گاهی در جواب تعدادی سطرها مشابه می شوند، اگر می خواهيد تعداد سطرهای متمايز را بدست آوريد از COUNT DISTINCT استفاده کنيد.
مثال. تعداد افرادی که در بانک پول دارند را پيدا کن.
SELECT COUNT (DISTINCT customer_name)
FROM depositor;
مثال. تعداد افرادی که در هر شعبه بانک حساب دارند را پيدا کن.
SELECT branch_name, COUNT (DISTINCT customer_name)
FROM depositor, account
WHERE depositor.account_number = account.account_number
GROUP BY branch_name;
GROUP BY
در بسياری موارد تحليل آماری روی گروهی از داده ها موردنياز است. برای گروه بندی از عبارت GROUP BY استفاده کنيد.
مثال. اسامی کليه شعب و ميانگين موجودی حساب آنها را پيدا کن
SELECT branch_name,AVG (balance)
FROM account
GROUP BY branch_name;
HAVING
توابع تجمعی در عبارت WHERE کار نمی کنند. اگر می خواهيد با توجه به نتيجه توابع تجمعی شرطی داشته باشيد از عبارت HAVING استفاده کنيد. HAVING مانند عبارت WHERE کار می کند با اين تفاوت که روی آخرين داده حاصل کار می کند و اجازه استعمال توابع تجمعی را هم می دهد. البته هزينه اجرای آن بالاست بنابراين فقط در زمانی که واقعا نياز است استفاده کنيد.
مثال. اسامی کليه شعب را که ميانگين حساب آنها بيشتر از 1200 است را پيدا کن
SELECT branch_name,AVG (balance)
FROM account
GROUP BY branch_name
HAVING AVG (balance) > 1200;
ORDER BY
ترتيب رکوردها در نتيجه پرس و جو معمولا بدون نظم است. اگر می خواهيد جدول حاصل دارای نظم خاصی بر طبق يک يا چند فيلد باشد عبارت ORDER BY را به همراه فيلدهای موردنظر اضافه کنيد. برای ترتيب نزولی از DESC و برای ترتيب صعودی از ASC روی هر صفت خاصه استفاده می شود. پيش فرض ترتيب صعودی است.
مثال. اسامی کليه مشتريانی که وامی در شعبه Perryridge دارند را به ترتيب حروف الفبا ليست کن.
SELECT DISTINCT customer_name
FROM borrower, loan
WHERE borrower loan_number = loan.loan_number AND
branch_name = ‘Perryridge’
ORDER BY customer_nam;
NULL
ممکن است مقدار بعضی از صفات خاصه در رکوردها تهی باشد که توسط NULL مشخص می شود. وقتی فيلدی حاوی NULL است بيان کننده اين است که مقدار آن فيلد نامعلوم است يا مقداری در دنيای واقعی ندارد. عملگرهای مقايسه ای اگر روی NULL عمل کنند مقدار Unknown را برمی گردانند. گزاره IS NULL می تواند برای بررسی مقادير NULL استفاده شود. عملگر متضاد آن IS NOT است که مقاديری که NULL نيستند را پيدا می کند. نتيجه هر عبارت رياضی روی NULL برابر با NULL است. کليه توابع تجمعی به استثنای COUNT از مقدار NULL صرفنظر می کنند. مثال. تعداد وام هائی که ميزان وام آنها معين نيست را پيدا کن.
SELECT loan_number
FROM loan
WHERE amount IS NULL;
پرس و جوهای تودرتو
در SQL مکانيسمی برای پرس و جوهای تودرتو فراهم شده است. به عبارت ديگر يک عبارت SELECT می تواند درون ديگری قرار بگيرد تا نتيجه اجرای آن در شرط WHERE عبارت SELECT ديگر استفاده شود. عبارت SELECT دوم را يک پرس و جوی فرعی می نامند و حتما بايد يک فيلد را برگرداند يعنی فقط يک صفت خاصه در دستور SELECT آن بايد باشد. وقتی حاصل پرس و جوی فرعی بيشتر از يک سطر باشد از عملگرهای ALL، ANY، IN، NOT IN، EXISTS و NOT EXISTS برای گرفتن نتيجه مطلوب بايد استفاده کرد.
مثال. اسامی کليه مشتريانی که هم حساب وهم وام در بانک دارند را پيدا کن.
SELECT DISTINCT customer_name
FROM borrower
WHERE customer_name IN (SELECT customer_name FROM depositor );
مثال. اسامی کليه مشتريانی که از بانک وام گرفته اند ولی حساب ندارند را پيدا کن.
SELECT DISTINCT customer_name
FROM borrower
WHERE customer_name NOT IN (SELECT customer_name FROM depositor );
مثال. اسامی کليه مشتريانی که هم حساب وهم وام در شعبه Perryridge دارند را پيدا کن.
SELECT DISTINCT customer_name
FROM borrower, loan
WHERE borrower.loan_number = loan.loan_number AND branch_name = ‘Perryridge’ AND
branch_name, customer_name IN (SELECT branch_name, customer_name
FROM depositor, account WHERE depositor.account_number = account.account_number );
توجه. پرس و جوهای بالا ساده تر هم می تواند نوشته شود.
ترکيب پرس و جوها
گاهی می خواهيم نتيجه دو پرس و جو را با هم به نحوی ترکيب کنيم و يک جدول را بدست بياوريم. عملگرهای UNION، INTERSECT و EXCEPT برای ترکيب نتيجه دو پرس و جو می توانند استفاده شوند که به ترتيب مشابه عملگرهای اجتماع، اشتراک و تفاضل در جبر رابطه ای عمل می کنند. مجموعه فيلدهای دو پرس و جوئی که با هم ترکب می شوند بايد از نظر تعداد و نوع مطابق هم باشند. عملگر UNION جدولی شامل کليه سطرهای هردو پرس و جو را می دهد. سطرهای تکراری حذف می شوند مگر اينکه از عبارت UNION ALL استفاده شود.
عملگر INTERSECT سطرهای مشترک در نتيجه دو پرس و جو را بر می گرداند. سطرهای تکراری حذف می شوند مگر اينکه از عبارت INTERSECT ALL استفاده شود.
عملگر EXCEPT سطرهائی از نتيجه پرس و جوی اول که در نتيجه پرس و جوی دوم ظاهر نشده است را بر می گرداند. EXCEPT ALL سطرهای تکراری را حذف نمی کند.
مثال. اسامی کليه مشتريانی که هم حساب وهم وام در بانک دارند را پيدا کن.
SELECT customer_nameFROM borrower
UNION
SELECT customer_name FROM depositor;
JOIN
وقتی بخواهيم اطلاعاتی را از دو جدول بدست بياوريم می توانيم عمل الحاق را روی دو جدول انجام دهيم. عملگر JOIN رکوردهای گرفته شده از دو جدول را با هم ترکيب می کند و جدول ديگری را به عنوان نتيجه می دهد. شرط الحاق نحوه جفت کردن رکوردهای دو جدول را تعيين می کند. الحاق دارای انواع مختلفی نظير الحاق طبيعی و الحاق خارجی است. نوع الحاق تعيين می کند چه رکوردهائی از هر جدول که جفتی در جدول ديگر ندارند در جدول نتيجه بايد اضافه شوند.
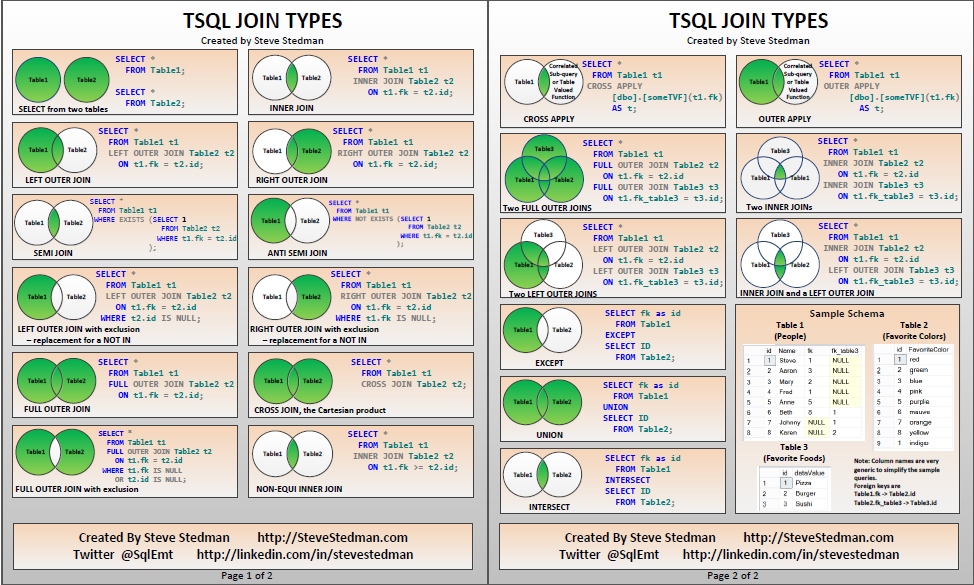
Natural Join
در الحاق طبيعی کليه سطرهائی که فيلدهای همنام آنها که در هردو جدول دارای يک مقدار هستند، درنظر گرفته می شود. جدول حاصل تنها شامل يک ستون از ستونهای هم نام خواهد بود.
مثال. اسامی وام گيرنده ها به همراه وام های گرفته شده از بانک را پيدا کنيد.
SELECT *
FROM borrower NATURAL JOIN loan;
Outer Join
در الحاق خارجی نيازی نيست رکوردهای دو جدول حتما رکورد مطابقی در جدول ديگر داشته باشند. الحاق خارجی، بسته به جدولی که همه سطرهایش نگهداشته می شود، به سه دسته الحاق چپ، راست و کامل تقسيم می شود.
LEFT OUTER JOIN کليه مقادير جدول سمت چپ خود را بعلاوه مقاديری از جدول سمت راست که مطابقت دارند می دهد. RIGHT OUTER JOIN کليه مقادير جدول سمت راست خود را می دهد بعلاوه مقاديری از جدول سمت چپ که رکوردهايش جور هستند. FULL OUTER JOIN نتيجه الحاق خارجی چپ و راست را با هم ترکيب می کند. الحاق خارجی داده های مفقود را، برای سطرهائی که شرط الحاق در آنها برقرار نبوده، با NULL پر می کند.
مثال. اسامی کليه وام گيرنده ها به همراه ميزان وامی که گرفته اند را پيدا کنيد.
SELECT *
FROM borrower LEFT OUTER JOIN loan
ON borrower.loan_no = loan.loan_no;
مثال. مقدار کليه وام های گرفته شده از شعبه Perryridge را به همراه نام وام گيرنده ها پيدا کنيد.
SELECT *
FROM borrower RIGHT OUTER JOIN loan
ON borrower.loan_no = loan.loan_no
WHERE loan.branch_name = ‘Perryridge’;
DELETE
فرمان DELETE اجازه حذف سطرهائی از يک جدول را می دهد. فرم کلی دستور به شکل زير است:
DELETE FROM table_name WHERE condition;
کليه رکوردهائی که شرط WHERE در آنها برقرار است از جدول حذف می شوند. اگر شرطی بيان نشود کليه رکوردهای جدول حذف خواهند شد.
دستور DELETE هيچ رکوردی را به عنوان خروجی بر نمی گرداند.
مثال. کليه رکوردهای وام گيرندگان را حذف کن.
DELETE FROM borrower;
مثال. کليه رکوردهایی که حسابی در شعبه Perryridge دارند را حذف کن.
DELETE FROM account
WHERE branch_name = ‘Perryridge’;
INSERT
دستور INSERT اجازه اضافه کردن رکوردی به يک جدول را می دهد. فرم کلی آن به صورت زير است:
INSERT INTO table_name
(column_list)
VALUES (value_list);
Column_list ليست فيلدهائی است که مقادير به آنها نسبت داده خواهد شد و اگر برای همه فيلدها مقداری درنظرگرفته شود می تواند حذف شود. value_list مجموعه ای از مقادير است که برای هر فيلد در ليست column_list يا فيلدهای جدول که در دستور CREATE TABLE تعريف شده اند مقداری دارد. تعداد ستون ها و مقادير آنها بايد يکسان باشد. اگر فيلدی ذکر نشود مقدار پيش فرض آن درنظر گرفته می شود. به فيلدهائی که در دستور CREATE TABLE به عنوان PRIMARY KEY يا با محدوديت NOT NULL تعريف شده اند بايد مقداری نسبت داده شود. مثال. حساب جديدی را با شماره A–9732 و با موجودی 1200 در شعبه Perryridge اضافه کن.
INSERT INTO account
VALUES (‘A-9732’, ‘Perryridge’,1200);
يا
INSERT INTO account
(branch_name, balance, account_number)
VALUES (‘A-9732’, ‘Perryridge’,1200);
مثال: اضافه کردن رکورد جديدی در جدول account با مقدار موجودی null به صورت زير انجام می شود.
INSERT INTO account
VALUES (‘A-777′,’Perryridge’, null );
UPDATE
دستور UPDATE اجازه تغيير داده های درون يک جدول را می دهد. اين دستور هيچ رکوردی را اضافه يا حذف نمی کند. شکل کلی آن به صورت زير است:
UPDATE table_name
SET column_name = value, column_name=value, …
WHERE condition;
در کليه رکوردهائی که شرط در آنها برقرار بوده است مقدار فيلدی که نامش در عبارت SET تعيين برابر با مقدار جديد می شود. دستور UPADTE ممکن است روی يک يا چند رکورد در يک جدول تاثير بگذارد. مثال. حساب هائی که موجودی آنها بيشتر از 10000 است را به ميزان 6% افزايش بده.
UPDATE account
SET balance = balance * 1.06
WHERE balance > 10000;
منابع:
http://www.hpkclasses.ir/Courses/DataBase/db0800.html
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 6165
برچسب(Structured Query Language) DBMS RDBMS SQL Server ، MySQL و Oracel TSQL اس کیو ال دستورات SQL دستورات پایگاه داده مروری بر TSQL
نوشته های مرتبط








همچنین ببینید
مورد استفاده پایگاه داده های غیر رابطه ای (NOSQL)
مورد استفاده پایگاه داده های غیر رابطه ای یا NOSQL بانکهای اطلاعاتی نوین که تحت …
