 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
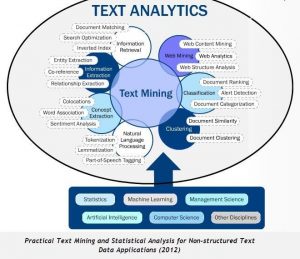
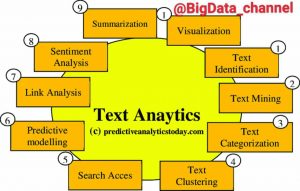
مراحل متن کاوی و پردازش متن به زبان خلاصه
عناوين مطالب: '
مقدمه ای بر مراحل متن کاوی
امروزه بخش وسیعی از دانش بهصورت متن، مستندات و دیگر صورتهای رسانهای نگهداری میشوند که همه آنها بهصورت غیر ساختاریافته هستند. یکی از کاربردهای دادهکاوی، متنکاوی است. ﺑـﺮاي درﻳﺎﻓﺖ داﻧﺶ از اﻃﻼﻋﺎت ﻳﻚ ﻣﺘﻦ، ﻻزم اﺳﺖ اﺑﺘﺪا آن را درك ﻛـﺮد، ﺳـﭙﺲ ﭘـﺮدازش ﻛﺮد ﺗﺎ ﻓﻬﻤﻴﺪ ﭼﻪ ﻣﻌﺎﻧﻲ و ﻣﻔﺎﻫﻴﻤﻲ در آن ﻣﻮﺟﻮد اﺳﺖ؛ ﭼﻪ ارﺗﺒﺎﻃﻲ ﻣﻴﺎن ﻣﻔﺎﻫﻴﻢ وﺟﻮد دارد و از ﻣﻴﺎن اﻳﻦ ﻣﻔﺎﻫﻴﻢ ﻛﺪام ﺟﺪﻳﺪ و ﻛﺪام ﻗﺪﻳﻤﻲ اﺳﺖ؛ ازاینرو در ﻋﺼﺮ ﻓﻨـﺎوري، ﻫﺮ ﭼﻴﺰي ﺑﺎﻳﺪ ﺑﺘﻮاﻧﺪ بهصورت ﺧﻮدﻛﺎر، اﻧﺠﺎم ﺷﻮد. “درك ﻣﻌﻨﻲ ﻣﺘﻮن ” ﻧﻴﺰ از اﻳﻦ ﺟﻤﻠﻪ ﻛﺎرﻫﺎ ﻣﺤﺴﻮب میشود. متنکاوی، ﻛـﺎوش دادههای ﻣﺘﻨـﻲ (ﮔﺮوﻮر و ﻫﻤﻜـﺎران، 2004) و ﻳﺎ ﻛﺸﻒ داﻧﺶ در ﻣﺘﻦ[1]، از نامهای موردقبول در این زﻣﻴﻨﻪ ﻫﺴﺘﻨﺪ. (بهزاد لک، جلال رضایی پور 1392)
مفهوم متنکاوی که به دریافت تمام اطلاعات موردنیاز از دادههای متنی اشاره میکند، تقریباً عمری برابر با خود بازیابی اطلاعات دارد. بههرحال، متنکاوی دارای ویژگیهای منحصربهفرد و اساسی است که باعث شده بین آن و بازیابی اطلاعات تمیز قائل شوند. متنکاوی در به دست آوردن اطلاعات مفیدی از دادههای متنی که ذاتاً ساختار نیافته، غیر متشکل و نامنظم هستند، کمک میکند.
متنکاوی و یا کشف دانش از متن (Karanikas، 2002)، اشاره به فرآیندی میکند که باعث به دست آوردن الگوهای غیر بدیهی، جالب و باکیفیت بالا و همچنین اطلاعات و دانش از اسناد متنی ساختار نیافته میشود. متنکاوی که بهعنوان کشف دانش از متن نیز شناخته میشود با دادهکاوی تفاوت دارد، به این معنا که متنکاوی به جستجو در میان دادههای متنی برای استخراج کردن اطلاعات مفید میپردازد که معمولاً طبیعتی ساختار نیافته دارند، درحالیکه دادهکاوی سعی در کشف دانش از پایگاه دادههای ساختاریافته دارد. (Alwidian 2015)، دربیانی بسیار ساده، متنکاوی روند کشف و استخراج الگوهای معنادار و روابط از مجموعه متن است (حمیدرضا احمدیان 1395).
پردازش زبان طبیعی تلاش میکند همانطوری که مفاهیم زبان طبیعی بهوسیلهی انسان تجزیهوتحلیل میشود، برای کامپیوتر هم قابلفهم باشد (Charu C. 2011) تحقیقات حوزه پردازش زبانهای طبیعی به دنبال پاسخ برای سؤالهای زیر است:
ماشین چگونه معنای یک جمله یا یک سند را درک میکنیم؟ برای اینکه بفهمیم چه کسی چهکاری را انجام داده و یا زمانی را که چیزی اتفاق افتاده است، یا چه چیزی واقعیت دارد و چه فرض یا پیشبینیای کرده از چه معیارهایی استفاده میکنیم؟ چه کلماتی از اسم، فعل، قید و صفت تشکیلدهنده بلوکهای معنایی هستند؟ همبستگی مفهومی این کلمات در ساختار جمله و در متن نسبت به یکدیگر چگونه است؟ و اینکه آیا در نزدیک شدن به معنای واقعی یک متن کمک خواهد کرد؟
اﻳﻦ ﺣﻮزه، ﺗﻤﺎم فعالیتهایی ﻛﻪ بهنوعی ﺑﻪ دﻧﺒﺎل ﻛﺴﺐ داﻧﺶ از ﻣﺘﻦ ﻫﺴﺘﻨﺪ را ﺷﺎﻣﻞ میشود. تحلیل دادههای ﻣﺘﻨﻲ ﺗﻮﺳﻂ ﻓﻨﻮن ﻳﺎدﮔﻴﺮي ﻣﺎﺷﻴﻦ، ﺑﺎزﻳﺎﺑﻲ اﻃﻼﻋـﺎت ﻫﻮﺷـﻤﻨﺪ، ﭘﺮدازش زﺑﺎن ﻃﺒﻴﻌﻲ ﻳﺎ روشهای ﻣﺮﺗﺒﻂ دﻳﮕﺮ، ﻫﻤﮕﻲ در زﻣﺮه ﻣﻘﻮﻟﻪ ﻳﺎدﮔﻴﺮي ﻣﺘﻦ ﻗـﺮار ﻣﻲﮔﻴﺮﻧﺪ. ﻳﻜﻲ از روشهایی ﻛﻪ ذﻛﺮ ﺷﺪ، اﺳﺘﻔﺎده از ﻓﻨـﻮن ﻳـﺎدﮔﻴﺮي ﻣﺎﺷـﻴﻦ درزمینه ﭘﺮدازش ﻣﺘﻦ اﺳﺖ. ﻣﺴﺌﻠﻪ قابلتأمل اﻳـﻦ اﺳـﺖ ﻛـﻪ اﻳـﻦ روشها، در اﺑﺘـﺪا در ﻣـﻮرد دادههای ﺳﺎﺧﺘﺎرﻳﺎﻓﺘﻪ ﺑﻪ ﻛﺎر ﮔﺮﻓﺘﻪ ﺷﺪﻧﺪ و ﻋﻠﻤﻲ ﺑﻪ ﻧﺎم دادهکاوي را به وجود آوردﻧـﺪ. دادههای ساختاریافته ﺑﻪ دادههایی گفته میشود ﻛﻪ بهطور ﻛـﺎﻣﻼً ﻣﺴـﺘﻘﻞ از ﻫﻤـﺪﻳﮕﺮ وﻟﻲ ﻳﻜﺴﺎن ازلحاظ ﺳﺎﺧﺘﺎري در ﻳـﻚ ﻣﺤـﻞ گردآوریشدهاند.
اﻧـﻮاع ﺑﺎﻧـکهـﺎي اﻃﻼﻋﺎﺗﻲ را میتوان بهعنوان نمونههایی از اﻳﻦ دﺳﺘﻪ اﻃﻼﻋﺎت ﻧﺎم ﺑﺮد. در این صورتمسئله دادهکاوی ﻋﺒﺎرت است از ﻛﺴﺐ اﻃﻼﻋﺎت و داﻧﺶ از اﻳﻦ ﻣﺠﻤﻮﻋﻪ ساختیافته؛ اﻣـﺎ در ﻣﻮرد ﻣﺘﻮن ﻛﻪ ﻋﻤﺪﺗﺎً غیر ساختاریافته ﻳﺎ ﻧﻴﻤﻪ ساختیافته ﻫﺴـﺘﻨﺪ؛ اﺑﺘـﺪا ﺑﺎﻳـﺪ ﺗﻮﺳـﻂ روشهایی، آنها را ﺳﺎﺧﺘﺎرﻣﻨﺪ ﻛﺮد و سپس از اﻳﻦ روشها ﺑﺮاي اﺳـﺘﺨﺮاج اﻃﻼﻋـﺎت و داﻧﺶ از آنها اﺳﺘﻔﺎده ﻛﺮد. (بهمن حاتمی ناغانی، مسعود عابسی 1395). در ادامه به مراحل متن کاوی می پردازیم.
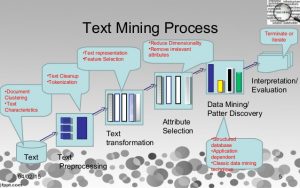
گامهای و مراحل متن کاوی
در پژوهشهای انجامشده، برای متنکاوی گام هایی ذکرشده که در زیر به عناوین مراحل متن کاوی اشارهشده است (Chiwara 2006). و در ادامه به توضیح هر گام می پردازیم.
- انتخاب متن
- پردازش متن
- تبدیل متن به صفات خاصه
- انتخاب صفات خاصه از متن
- دادهکاوی بر روی متن (کشف دانش از متن)
- تفسیر و ارزیابی خروجی متن کاوی
انتخاب متن
در این قدم مجموعه اسنادی که قصد کاوش در بین آنها وجود دارد، بهصورت متن موجود هستند. در این گام از مراحل متن کاوی باید اسناد متنی یا داده های متنی که ارزش تحلیل را دارند. گرد آوری شود.
پردازش متن
در این قدم فرآیندهایی همچون فرمت، ساخت توکن، پاکسازی متن انجام میشود. در طی فرآیند جمعآوری متون، ممکن است که آنها بهخوبی سازمانیافته نباشند در این صورت بهعنوان اطلاعات ازدسترفته یا یکپارچگی متون غیرعقلانی تفسیر میشوند. اگر متون، بهدرستی بررسی نشوند آنگاه متنکاوی ممکن است منجر به پدیده «ایجاد خروجی غلط توسط ورودی بیکیفیت و ناصحیح[2]» شود. در فاز پیشپردازش، مستندات به تعداد ثابتی از ردهبندیهای از پیش تعریفشده سازماندهی میشوند. پیشپردازش، پیادهسازی موفقیتآمیز تحلیل متن را تضمین میکند اما ممکن است که زمان پردازش قابلتوجهی را مصرف کند خروجي فاز پیشپردازش به دو صورت زیر است: (George Forman, 2008)
- مبتنی بر سند
در این حالت نمايش درست مستندات اهمیت دارد. براي مثال تبديل اسناد به يك فرمت مياني و نيمه ساختیافته، يا به كار بردن يك نمایه بر روی آنها يا هر نوع نمايش ديگري كه كار كردن با اسناد را مؤثر ميكند. هر موجوديت در اين نمايش درنهایت بازهم يك سند خواهد بود.
- مبتني بر مفهوم
در این حالت نمايش اسناد بهبود بخشيده ميشود، مفاهيم و معاني موجود در سند و ارتباط ميان آنها و هر نوع اطلاعات مفهومي ديگري كه قابلاستخراج است، از متن استخراج ميشود. در اين حالت نه با خود موجوديت بلكه با مفاهيمي كه از اين مستندات استخراجشدهاند، مواجه هستيم.
تبدیل متن به صفات خاصه
در این قدم از متون پردازششده صفات خاصه استخراج میشود. فرایند استخراج ویژگی شامل مراحل زیر است (علیرضا درخشان، 1396):
- تجزیهوتحلیل مورفولوژیک[3]: این روش با تکتک کلمات موجود در یک سند متنی سروکار دارد و شامل مراحل زیر است:
- توکن بندی: در این مرحله سند از طریق حذف فضاهای خالی، کاما و کلیه علائم نگارشی به دنبالهای از رشته لغات تبدیل میشود.
- حذف لغات توقف: در این مرحله لغات بازدارنده مانند a، The و یا or از متون حذف میشوند. این مرحله از طریق کاهش تعداد لغات موجب افزایش اثربخشی و کارایی میشود.
- ریشهیابی: این مرحله تکنیک نرمالسازی زبانشناسی است و برای تبدیل لغت به فرم ریشه به کار میرود. مثلاً لغت honesty به لغت honest و یا walking به walk تبدیل میشود.
- تجزیهوتحلیل نحوی: این قسمت بر روی ساختار یکزبان که اغلب نحو نامیده میشود تأکید دارد. بهعنوانمثال زبان انگلیسی شامل اسم، فعل، قید، نقطهگذاری و دیگر بخشهای گفتاری میشود (Li 2012).
- برچسبگذاری اجزای واژگانی کلام: این نشانهگذاری معمولاً برای اضافه کردن دانش دستوری به یک لغت از یک جمله به کار میرود. اگر کلاس واژگانی کلمه شناختهشده باشد، آنگاه انجام تجزیهوتحلیل زبانی راحتتر است.
- پارسینگ: تکنیکی است که برای بررسی ساختار گرامی یک جمله به کار میرود. جملات در یک ساختاری شبیه درخت نمایش داده میشوند که اصطلاحاً به آن درخت پارس گفته میشود که در اصل برای تجزیهوتحلیل درخواستهای دستور زبانی صحیح در یک جمله به کار میرود. درخت پارس میتوان با دو رویکرد بالا به پایین و یا پایین به بالا ساخته شود.
- تجزیهوتحلیل معنایی: بر یافتن ارتباط معنادار بین واژگان تأکید دارد. چگونه معنای یک جمله به معنای عبارات، کلمات و تکواژههای تشکیلدهنده آن مربوط میشود.

مراحل متن کاوی انتخاب صفات خاصه از متن

در این قدم تعدادی از صفات خاصه برای انجام کاوش انتخاب میشوند، زیرا همه صفات خاصه برای انجام کاوش مفید واقع نیستند. انتخاب ويژگی شامل 3 تکنیک زیر است (Hwang 2014):
هدف اصلی از انتخاب ویژگی، از بین بردن اطلاعات نامربوط و مزاحم از متن موردنظر است. در این قسمت مهمترین ويژگیها را از طریق امتیاز لغات انتخاب میکند. اهمیت لغت در سند توسط نمره اختصاص دادهشده به آن مشخص میشود. سند متن بهعنوان یک مدل فضای برداری ارائه میشود. در این مدل هر بعد نشاندهنده یک اصطلاح[4] مجزا، از یک کلمه، کلمه کلیدی یا یک عبارت است. ماتریس سند توسط n سند و m اصطلاح نشان داده میشود. مقادیر غیر صفر در این ماتریس نشاندهنده حضور اصطلاح در سند است.
- تکنیک اندیس گذاری معناییِ نهفته
در روشهای قبلی متون بهتنهایی و بدون در نظر گرفتن کل مجموعه پردازش میشدند و اگر تصمیمی مبنی بر جواب بودن یک متن گرفته میشد، آن تصمیم کاملاً متکی به همان متن و مستقل از متون دیگر گرفتهشده و هیچ توجهی به وابستگی موجود بین متون مختلف و ارتباط بین آنها نمیشد که این مسئله یکی از عوامل پایین بودن دقت جستجوها و ناکارآمدی آنها به شمار میرفت. این روش بر پایه تحلیل معنایی نهفته بناشده است؛ که گامی را به مجموعه مراحل موجود در پروسه اندیس گذاری اضافه میکرد. این روش بجای آنکه در اندیس گذاری تنها یک متن را در نظر بگیرد، کل مجموعه اسناد را باهم و در کنار یکدیگر در نظر میگرفت تا ببیند که چه اسنادی لغات مشابه با لغات موجود در سند موردبررسی رادارند.
هنگامیکه بردارهای دادهای دارای ابعاد بسیار بالایی هستند، استفاده از الگوریتمهای تشخیص الگو و یا تحلیل داده که مکرراً مشابهات و یا فاصله فضای دادههای اصلی را محاسبه میکنند غیرممکن است. LSI تطبیق واژگانی را از طریق اتخاذ یک رویکرد معنایی بهبود میبخشد، درحالیکه تکنیک نگاشت تصادفی یک نقشه از محتوای یک مجموعه سند بزرگ ایجاد میکند. هر منطقه انتخابشده در یک نقشه بیشتر میتواند برای استخراج اسناد جدید در موضوعات مشابه استفاده شود. تکنیک تصادفی شامل ماتریس تصادفی است که از ضرب بردارهای اصلی به دست میآید و یک بردار کاهشیافته ایجاد میکند. (دکتر علیرضا درخشان، شمیم ظهوریان 1396)
دادهکاوی بر روی متن (کشف دانش از متن)
با توجه به صفات خاصهی انتخابشده در قدم قبل، در این قدم بر روی این صفات خاصه برای استخراج الگوهای مناسب، کاوش انجام میشود. همچنین موارد زیر به عنوان انواع روش های داده کاوی بر روی متن یا به عبارتی متن کاوی متصور است.
تفسیر و ارزیابی خروجی متن کاوی
درنهایت نتایج بهدستآمده مورد ارزیابی قرارگرفته و برای موارد مختلف تفسیر و استفاده میشود. در ارزیابی معمولا معیارهای زیر متصور است.
- تشکیل ماتریس اختلاط (confusion matrix)
- دقت (Accuracy): به طور کلی، دقت به این معناست که مدل تا چه اندازه خروجی را درست پیشبینی میکند:
- صحت (Precision): وقتی که مدل نتیجه را مثبت (positive) پیشبینی میکند، این نتیجه تا چه اندازه درست است؟
- Recall: زمانی که ارزش false negatives بالا باشد، معیار Recall، معیار مناسبی خواهد بود.
- F1 Score: معیار F1، یک معیار مناسب برای ارزیابی دقت یک آزمایش است. این معیار Precision و Recall را با هم در نظر میگیرد. معیار F1 در بهترین حالت، یک و در بدترین حالت صفر است.
[1] -Knowledge Discovery in Textual Databases (KDT)
[2] -garbage in garbage out
[3]– Morphological analysis
[4] -Term
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 10438
برچسبNLP text mining TP پردازش زبان طبیعی پردازش متن پیش پردازش متن گامهای متنکاوی متن متن غیر ساخت یافته متن کاوی مراحل متن کاوی
نوشته های مرتبط










همچنین ببینید
مجموعه داده اسامی مکان برای تشخیص موجودیت های مکانی در پردازش زبان طبیعی
عناوين مطالب: 'مقدمه ای بر اسامی مکان:کاربردهای (Named-entity recognition) NERروشهای تشخیص اسم مکاندانلود دیتاست اسامی …

دانلود مجموعه داده اخبار با طبقه بندی موضوعی (classification)
به منظور استفاده دانشجوبان عزیز در انجام پایان نامه حدود بیست هراز مجموعه داده اخبار …
