 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
مراحل پیشپردازش متن خبر فارسی
پیشپردازش متن فارسی
برای پردازش زبان طبیعی و انجام عمليات خودکار بر روي متن مانند ترجمه، خلاصهسازي، تصحيح املا، استخراج کلمات کلیدی، خوشه بندی، طبقه بندی و غيره، نيازمند ابزارهايي جهت پيشپردازش و آمادهسازي متون هستيم. پیش پردازش[1] داده ها، مهمترین مرحله در فرایند کشف دانش از داده های متنی میباشد. پردازش متن به صورت خام امکانپذیر نیست و لازم است با انجام چند مرحله پیشپردازش، متن را براي انجام پردازشهاي لازم آماده کرد. پیچیدگی پیشپردازش داده ها، به منابع داده استفاده شده بستگی دارد. اگر دادههای وارد شده نویزدار و غیر قابل اطمینان باشند، کشف دانش از آنها بسیار مشکل میشود. مراحل آمادهسازی و فیلتر کردن داده ها، زمان قابل توجهی از زمان پردازش را به خود اختصاص خواهد داد. پیشپردازش دادهها شامل تمیز کردن، انتخاب نمونه، نرمالسازی، تبدیل، استخراج ویژگیها، انتخاب و غیره است. خروجی به دست آمده از فرآیند پیشپردازش داده ها، یک مجموعه داده پالایش شده است که میتواند برای آموزش الگوریتمهای متنکاوی استفاده شود. در این فرآیند حذف ایستواژه ها[2] بر میزان و کیفیت قوانین استخراج شده تأثیر قابل توجهی دارد.
روشهای پیشپردازش داده های متنی به دو صورت انجام میشود. دسته اول روشهای وابسته به زبان هستند که بر اساس برخی قوانین نحوی و ساختاری زبان انجام میشوند. روشهای دیگر، مستقل از زبان هستند و بیشتر بر مبنای پیکرههای زبانی و با استفاده از روشهای یادگیری ماشین صورت میگیرد که به تحلیل معنایی شهرت دارند. البته در برخی موارد ترکیبی از هر دو روش مورد استفاده قرار میگیرد. از اینرو طراحی و پیادهسازی این ابزارها برای زبانهای مختلف به روشهای مختلف و مخصوص زبان مربوطه صورت ميگيرد.
تشخیص زبان
اولین گام در پردازش زبان طبیعی، مشخص کردن زبان متن میباشد. تشخیص زبان[3] میتواند به عنوان یک تکنیک فیلترینگ در بازیابی اطلاعات برای کمک به کاربران علاقهمند به اطلاعات نوشته شده با یک زبان خاص به کار رود. علاوه بر این، از آنجا که بسیاری از تکنیکهای پیشپردازش زبان نیازمند شناسایی زبان سند میباشند، تشخیص زبان یک گام مهم پیشپردازش برای تکنیکهای پردازش زبان دیگر مانند بنواژهیابی و یا ترجمه ماشینی است. روش کار تشخیص زبان به این صورت است که ابتدا یک مدل برای سند و یک مدل برای هریک از زبانهای مورد نظر تهیه میشود و پس از آن با مقایسه مدل سند و مدل زبانها، زبان سند تعیین میگردد. ابزارهای زیادی برای تشخیص زبان سندها ارائه شدهاند که تعدادی از آنها عبارتاند از: Java Text Categorization Library، Apache Tika و JLangDetect.
جداساز جملات
مرحله دیگری که بسته به نیاز در NLP انجام میشود، جداسازی جملات[4] است. یک جمله زمانی تمام میشود که یک کاراکتر پایانی جمله مانند “نقطه” یا “؟” مشاهده شود. اين ابزار با توجه به کاراکترهاي جداکننده جمله، توانايي تشخيص جملات را در متن ورودي دارد. براي ايجاد اين ابزار بايد ابتدا تمامي کاراکترها، نمادها و احياناً قواعد دستوري که باعث شکسته شدن جملات ميشوند، شناسايي گردند. با توجه به پايه بودن جمله در بسياري از پردازشهاي زباني، خروجي دقيق اين ابزار از درجه اهميت بالايي برخوردار است. از نمونه هاي زبان انگليسي آن ميتوان به OpenNLP، Stanford NLP، NLTK و Freeling اشاره کرد.
هنجارساز
هنجارساز[5] متن نیز فرآیندی پردازشی است که متن را به یک حالت استاندارد تبدیل میکند و شامل مراحل متعددي براي اصلاح اشتباهات سهوي کاربران و چندگانگی نوشتاري در زبان فارسی است. در هنجارسازی و استاندارد کردن یک متن باید به نوع متن، زبان، موضوع و پردازشهایی که پس از آن قرار است بر روی آن انجام شود توجه داشت. هنجارسازی واحدهای متنی، به طوری كه برای استفاده در پردازشهای بعدی توسط ماشین قابل استفاده باشند، امری بدیهی و لازم است .
هنجارساز متن شامل طبقهبندی نهادهای متنی مانند تاریخ، زمان، عدد، مبلغ ارز و غیره است. هنجارسازی عمدتاً شامل حذف علائم، نقطهگذاری، تبدیل کل متن به حروف کوچک یا بزرگ[6]، تبدیل اعداد به کلمات، گسترش اختصارات و غیره میباشد. البته این نکته حائز اهمیت است که برای هنجارسازی روش همه منظورهای وجود ندارد. در این فرآیند مشکلاتی مانند وجود encodingهای مختلف برای بعضی از كاراكترها مانند «ی» و «ك»، روشهای مختلف چسبیدن «وندها» به كلمات اصلی، روشهای مختلف اتصال اجزای كلمات مركب و كلمات چند املایی مطرح هستند.
واحدساز
تکهتکه کردن سند به قسمتهای کوچک به نام واحد را واحدساز(Tokenizer) گویند. براي شکستن يک متن بر اساس واحدهاي با معني مانند کلمه، پاراگراف، جمله و نمادهاي معنادار از واحدساز استفاده میشود. واحدسازی در سطح کلمات رخ میدهد و واحدهای استخراج شده میتوانند به عنوان ورودی ماژولهای دیگر مانند ریشهیاب و برچسبگذار استفاده شود. عموماً بعد از این مرحله حذف ایستواژهها انجام میشود. متن بر اساس انتخاب هر کدام از اين واحدها و با استفاده از tab یا Space شکسته خواهد شد [15].
حذف ایست
واژه ها
پس از هنجارسازی متن، بایستی ایستواژه ها را نیز برای برخی کاربردها حذف کنیم .ایستواژه ها تعدادی کلمه پرتکرار هستند که شامل عمومیترین افعال، ضمایر، قیدها، حروف ربط و حروف اضافه میباشند. ایست واژه ها مفهوم خاصی ندارند و از لحاظ معنایی با اهمیت نیستند ولی در جملات و متنها بسیار تکرار میشوند. «اگر»، «ولی»، «و»، «که» در زبان فارسی و to, for, about در زبان انگلیسی از جمله ایست واژههایی هستند که باید در مراحل پیشپردازش حذف شوند. در اغلب کاربردهای متن، حذف این کلمات، نتایج پردازش را به شدت بهبود میدهد و سبب کاهش بار محاسبات و افزایش سرعت پردازش خواهد شد. به همین دلیل این کلمات را غالباً در فاز پیش پردازش حذف میکنند. برای زبان فارسی چندین لیست از این کلمات منتشر شده است که بهطور میانگین شامل 800 کلمه میباشند. برای حذف این کلمات عموماً فهرستی از این کلمات از پیش تهیه میشود و سپس در صورت رخداد این کلمات در متن، از سند حذف میشوند [19]. نمونهای از ایست واژههای زبان فارسی در جدول 2‑1 آمده است:
|
به |
اگر |
با |
را |
باشد |
|
|
اکنون |
است |
زیرا |
برای |
اینک |
هست |
|
البته |
شد |
چون |
بالاخره |
اینطور |
بعدا |
|
اما |
کرد |
باید |
اینقدر |
بدون |
حدودا |
|
حتما |
حتی |
حالا |
بله |
انگار |
خصوصا |
جدول زیر نمونهای از ایستواژه های متون فارسی
ریشه یاب و بن واژه یاب
ریشه یابی و بنواژهیابی از اقداماتی است که بنا به نیاز در زمره تحلیل صرفی دسته بندی میشود. ریشهیابی اصطلاحی است که برای تعریف فرآیند کاهش دادن تعداد حروف یک کلمه و رسیدن به ریشه آن بهکار میرود. منظور از ریشه در این تعریف، ریشه زبانی نیست و هدف این است که فرمتهای گوناگون یک کلمه دارای ریشه های یکسان باشند. معمولاً ریشهیابی لغات بر اساس قواعد ساختواژهای و سپس حذف پسوندها میباشد و پس از واحدسازی متن انجام میشود. یکی از اقدامهای مؤثر برای استخراج ریشه کلمه، حذف پیشوندها است. برای حذف پسوندها از آنالیزهای آماری و دادهکاوی استفاده میشود، که این روش هم میتواند راهی برای تشخیص ریشه باشد. این روش براي ریشهیابی لغات و تشخیص نوع کلمه ساخته شده از آن ریشه (اسم مکان، اسم زمان، حالت فاعلی، مفعولی و …) استفاده میشود [23]. معروفترین الگوریتم ریشهیابی در انگلیسی porter است.
در فرهنگهای لغت، “بنواژه” (lemma)، معنایی انتزاعی از صورتهای مختلف یک واژه است. بنواژهیابی نیز تحت عنوان تقلیل و سادهسازی صورتهای گوناگون صرفی یک واژه و گزینش یک صورت پایه از کلمات تعریف شده است. بن واژه معنایی انتزاعی از صورتهای مختلف یک واژه است. در زبانشناسی محاسباتی، بنواژهیابی کردن، فرایندی الگوریتمی است که یک کلمه بر اساس معنای آن تحلیل میشود. بر خلاف ریشهیابی، بنواژهیابی، شناسایی صحیح بخشی از گفتار و معنای یک کلمه در یک جمله و همچنین در محدوده اطراف آن جمله، جملات همسایه یا حتی کل سند میباشد. در بسیاری از زبانها، کلمات در چندین شکل نحوی ظاهر میشوند. به عنوان مثال، به زبان انگلیسی، فعل ‘to walk’ به معنای راه رفتن، ممکن است به عنوان ‘walk'”، ” walked “، ” walks” و ” walking” ظاهر میشود. حالت پایه، “walk”، بنواژه برای این کلمه است. در زبان فارسی نیز معانی مشابهی مانند دموکراسی، دموکراتیک و دموکراتیزاسیون وجود دارد که بنواژه آن کلمه دموکراسی است. با این حال، فرآیند ریشهیابی معمولاً سادهتر و سریعتر اجرا میشود.
هدف هر دو ابزار بنواژهیابی و ریشهیابی کاهش اشکال فراوان و بعضی از اشکال متداول مشتق شده از یک کلمه به یک شکل پایه مشترک و اغلب شامل حذف عبارات مشتق شده است.
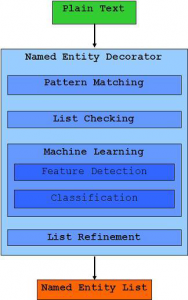
تشخیص موجودیتهای اسمی
تشخیص موجودیتهای اسمی فرآیندی است که هدف از آن تشخیص و شناسایی کلمات یا عباراتی است که نمایانگر یک موجودیت میباشند. این فرآیند برای تشخیص اسامی و نوع آنها از قبیل نام افراد، سازمانها، مکانها و غیره بکار میرود. تشخیص موجودیتهای اسمی به طور خاص میتواند ما را در حل مسائلی مانند رفع ابهام و تشخیص هویت اصلی اشخاص با اسامی مشترک از روی موضوع متن و با کمک ابزارهای جانبی یاری دهد [6]. شکل 2‑1 معماری یک سیستم NER را نشان میدهد.
نمونهای از کاربردهای NER شامل موارد زیر است:
- یافتن نقل قول و ارجاعات در مقالات علمی یا یافتن ارتباط بین مقالات
- تشخیص ارتباط میان اشخاص و انجمنها با استفاده از اسامی و ارجاعات
- بهینه کردن پاسخهای یک موتورِ جستجو در زمینهی یافتن اسامی
برای تشخیص اینکه یک کلمه اسم است، راه های مختلفی وجود دارد که از جملهی آنها مراجعه به لغتنامه، استفاده از شبکه واژگان، در نظر گرفتن ریشهی کلمه، استفاده از قواعد نحوی ساختواژه و غیره میباشد. در این فرآیند پس از تشخیص اسمها با استفاده یک لغتنامه از اسامی افراد، مکانها، مقادیر عددی و … نوع اسم تشخیص داده میشود. تشخیص درست واحدهای اسمی، یک نیاز مهم در حل مسائلی مانند پاسخگویی به سؤالات، سیستمهای خلاصهسازی، بازیابی اطلاعات، استخراج اطلاعات، ترجمهی ماشینی، تفسیر ویدئویی و جستجوی معنایی در وب است. از جمله نمونه های زبان انگلیسی این ابزار میتوان به Stanford NER وIllinois NER اشاره کرد.
استخراج کلمات کلیدی
استخراج کلمات کلیدی، فرآیند شناسایی خودکار اصطلاحات به کار رفته در یک سند است. یکی از عملیاتهای مهم در فرآیندهای خوشه بندی، طبقه بندی، استخراج اطلاعات و مشخص کردن موضوع مورد بحث در یک سند، استخراج کلمات کلیدی متن است. عبارات کلیدی، اصطلاحات کلیدی و کلمات کلیدی عبارتاند از اصطلاحاتی که برای تعریف شرایطی که بیشترین اطلاعات مرتبط در سند را ارائه میدهند. اگرچه این اصطلاحات با هم متفاوت هستند، ولی عملکرد آنها یکسان است. با یافتن کلمات کلیدی میتوان راحتتر و در زمانی کوتاهتر به مفهوم یک متن، خبر یا مقاله پی برد. برای انتخاب کلمات کاندید به عنوان کلمات کلیدی، بایستی تمام کلمات، عبارات، اصطلاحات و مفاهیمی که میتوانند به طور بالقوه کلمات کلیدی باشند را استخراج میکنیم. سپس با استفاده از تکنیکهای پردازش متن و یادگیری ماشین، خواص هر کاندید محاسبه و یک نمره یا آستانه احتمالی به آن اختصاص مییابد. سپس تمام کاندیداها را میتوان به وسیله ترکیب خواص، برای انتخاب مجموعه نهایی کلمات کلیدی یک سند ارزیابی کرد. به عنوان مثال، یک عبارت کاندید در عنوان یک کتاب، به احتمال بسیار زیاد یک کلمه کلیدی است [31].
به طور کلی سه روش متداول برای استخراج کلمات کلیدی وجود دارد:
- روش TF-IDF
- روش مبتنی بر یادگیری ماشین
- ترکیب روشهای تحلیل آماری و زبان شناختی
استخراج کلمات کلیدی غالباً با استفاده از تکنیکهای یادگیری ماشین دارای نتایج بهتری است. لیکن استفاده از روشTF-IDF به دلیل سهولت و استفاده از منابع سیستمی کمتر، متداول میباشد.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
-
preprocessing ↑
-
Stop Word ↑
-
Language Detector ↑
-
sentence splitter ↑
-
در زبان غیر فارسی مانند انگلیسی یا فرانسه ↑
بازدیدها: 2254
برچسبپیش پردازش متن تحلیل اخبار تحلیل خبر تحلیل متن داده کاوی متن کاوی مراحل پیشپردازش مراحل پیشپردازش متن خبر فارسی
نوشته های مرتبط











همچنین ببینید

ایجاد انبارداده(DWH)، دریاچه داده(Data Lake)، بازار داده(Data Mart) و مکعب داده(Data Cube)
داده ها با توجه به حجم و کاربرد آنها در منطق هاي مختلف ذخيره سازي …
روش های داده کاوی (Data Mining) به زبان ساده
امروزه داده کاوی به عنوان پایه و مبنای تصمیم های مهم محسوب میشود. داده کاوی …
