 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آموزش الستیک سرچ (Elastic Search) نصب و اجرا
در این مبحث به آموزش الستیک سرچ (Elastic Search) میپردازیم. ElasticSearch یا (ES) یک موتور جستجو و تحلیل منعطف، قدرتمند، متن باز، توزیع شده، دسترسی بالا[1] و بلادرنگ میباشد که هسته شاخص گذار آن کتابخانه Lucene می باشد.گاهی از موتور جستجو به عنوان یک پایگاه داده مبتنی بر سند نیز یاد می شود.
عناوين مطالب: '
موتور جستجوی الستیک سرچ (Elastic Search)
الاستیک سرچ یک موتور جستجوی متن با امکانات فراوان از قبیل راحتی استفاده، مقیاس پذیری بالا، فیلترهای متنوع جستجو، تحلیلگرهای اختصاصی و سفارشی برای متون فارسی قبل از ایندکس و ذخیره در دیتابیس، دسته بندی نتایج و امکان گروه بندی و فیلتر ثانویه روی آنها، جستجوی فازی و تقریبی و مانند آنها را دارد. از ابتدا به منظور استفاده در محیط های توزیع شده پیاده سازی شده است ،جایی که اتکاپذیری و مقیاس پذیری باید وجود داشته باشد،ES توانایی حرکت آسان ماوراء جستجوی کاملا متنی ساده را به شما میدهد و رابطه ای اکثر زبانهای برنامه نویسی معروف را ارائه می دهد،ES وعده های بی حد و حصر استفاده از فناوری جستجو را ارائه میکند. علاوه بر قابلیت های مذکور قابلیت هایی دیگری نیز قابل ذکر است از قبیل:
- چندین شاخصی[2] : یک خوشه میتواند میزبان چند شاخصی که جدا از هم و یا به صورت یک گروه میباشند،باشد.
- مبتنی بر سند[3] : ذخیره سازی موجودیتهای پیچیده دنیای واقعی به صورت اسناد JSON انجام میگیرد. تمام فیلدها به صورت پیش فرض شاخصگذاری میشوند و تمام شاخصها در یک درخواست میتوانند استفاده شوند.
- مدیریت مغایرت[4] : یک کنترل کننده نسخه به منظور ممانعت از نابودی اطلاعات در زمان تغییرات همزمان
- رابطRESTful : استفاده از رابط RESTful به گونه ای که از JSON بر روی پروتکل HTTP استفاده میکند.
- ماندگاری در هر عملیات[5] : برای ES در ابتدا امنیت داده مهم است. تغییرات اسناد در گزارشهای تراکنشها در چندین نود در خوشه مورد نظر ثبت میشود تا امکان از دست رفتن داده به حداقل برسد.
- عدم استفاده از قالب ثابت[6] : ES به صورت اتوماتیک ساختار داده مورد نظر را از اسناد JSON استخراج کرده و پس از شاخصگذاری آن را قابل جستجو قرار میدهد. سپس بعدها با اعمال دانش خاص منظوره داده های شما، نحوه شاخصگذاری داده های شما را تعیین میکند.
الاستیک سرچ یکی از بهترین بانکهای اطلاعاتی سندگرا و همچنین جزء بهترین کتابخانه های جستجوی متن است که بر پایه کتابخانه معروف لوسین بنا شده است و علاوه بر سرعت بسیار بالا در پاسخگویی به انواع پرس و جوهای موردنیاز، توزیع شوندگی راحت در شبکه و سهولت بسیار زیاد در ورود داده، امروزه با افزودن داشبورد مدیریتی کیبانا و امکانات یادگیری ماشین و نیز ماژول هایی مانند LogStash و HeartBeat که به جمع آوری اطلاعات و لاگ ها از سرورهای مختلف می پردازد به یک گزینه بسیار ایده آل برای ذخیره و پردازش و مانیتورینگ داده های در جریان سیستم های عملیاتی معاصر تبدیل شده است. اگر به لیست بانکهای اطلاعاتی برتر دنیا هم در سایت db-engines نگاهی بیندازید، این بانک را جزء ده بانک اطلاعاتی مطرح امروزین خواهید یافت.
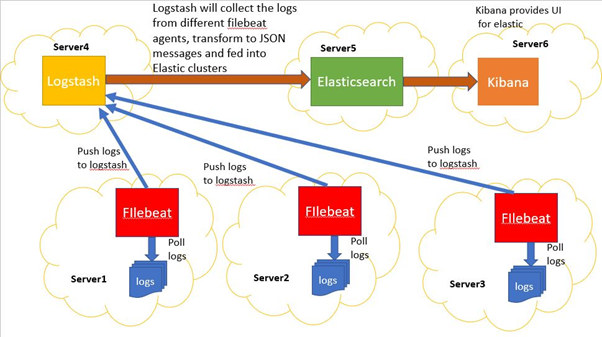
موتور شاخص گذار Lucene
این روژه در سال ۱۹۹۹ نوشته شدو در سایت source forge به صورت متن باز ارائه شد و بعدها به بنیاد آپاچی ملحق شد . این نرم افزار یک کتابخانه نرم افزاری بازیابی اطلاعات می باشد . این نرم افزار توسط java نوشته شده است . این نرم افزار به زبان های برنامه نویسی دیگر از جمله دلفی، پرل، C #، C + +، پایتون، روبی و PHP پورت شده است. این نرم افزار برای هر نرم افزاری که نیاز به شاخص گذاری و جستجوی متن به صورت کامل داشته باشد بسیار مفید خواهد بود . Lucene به صورت گسترده ای مورد قبول واقع شده و در موتور جستجوهای اینترنتی و محلی و جستجوی تک سایت مورد استفاده قرار می گیرد. .
در معماری منطقی هسته Lucene ایده ای نهفته است . این ایده متذکر می شود که یک سند حاوی فیلدهایی از متن هستند . این انعطاف پذیری به API های این نرم افزار اجازه می دهد که مستقل از فرمت فایل باشند . متن از هر فرمت WORD،HTML،Open Document و … می تواند استخراج شده و شاخص گذاری شود . این عمل بر روی تصاویر غیر قابل ممکن است .
Lucene شامل توابع و کتابخانه هایی برای خزش و پارس نمودن فایل های Html نمی باشد ولی پروژه های دیگری این قابلیت ها را به ارائه نموده اند.
آشنایی با مفاهیم و معماری الستیک سرچ (Elastic Search)
همانطور که گفتیم الاستیک سرج یک موتور منبع باز[7] ، جستجوی کامل متن[8] و تجزیه و [9]تحلیل بسیار مقیاس[10] پذیر است. و به شما امکان ذخیره، جستجو و آنالیز حجم عظیمی از داده ها را در زمان اندکی میدهد. در ادامه چند اصطلاح پرکاربرد در ES را معرفی و شرح میدهیم که برای شروع کار با این موتور الزامی است :
Near RealTime(nrt)
ES یک پلتفرم جستجوی نزدیک به زمان واقعی است این بدان معنی است که مدت زمانی که طول میکشد که یک سند از مرحله ایندکس به مرحله جستجو برسد بسیار ناچیز (Refresh Time) است.
Cluster
یک کلاستر مجموعه ای از یک یا تعداد بیشتری نود (Server) میباشد که این نودها در کنار یکدیگر کل داده
ها را نگه داری میکنند و امکان جستجو و ایندکس فدرالی را روی تمام نودها فراهم میکنند. یک کلاستر توسط نام خود شناسایی میشود و در حالت پیش فرص در ES نام کلاستر ElasticSearch میباشد. این نام بسیار مهم است زیرا یک نود تنها با داشتن نام کلاستر مورد نظر میتواند به آن متصل شود و روشن است که روی یک بستر شبکه، نام کلاسترها باید متمایز از دیگری باشد.
Node
هر نود میتواند یک سیستم جدا باشد که قسمتی از یک کلاستر را تشکیل میدهد. نودها محل ذخیره داده ها هستند و عملیات Search و Index بروی آنها انجام میشود. نودها هم مانند کلاستر توسط نام خود شناسایی میشوند و در حالت پیش فرض اگر نام نود توسط کاربر تعیین نشود ES از یک نام به صورت تصادفی از بین اسامی افراد و شخصیتهای مشهور به آن نسبت میدهد و نام هر نود در شناسایی آن ضروری است و در حالت پیشفرض تمام نودهای ایجاد شده به کلاستر پیش فرض ES یعنی ElasticSearch اضافه میشوند.
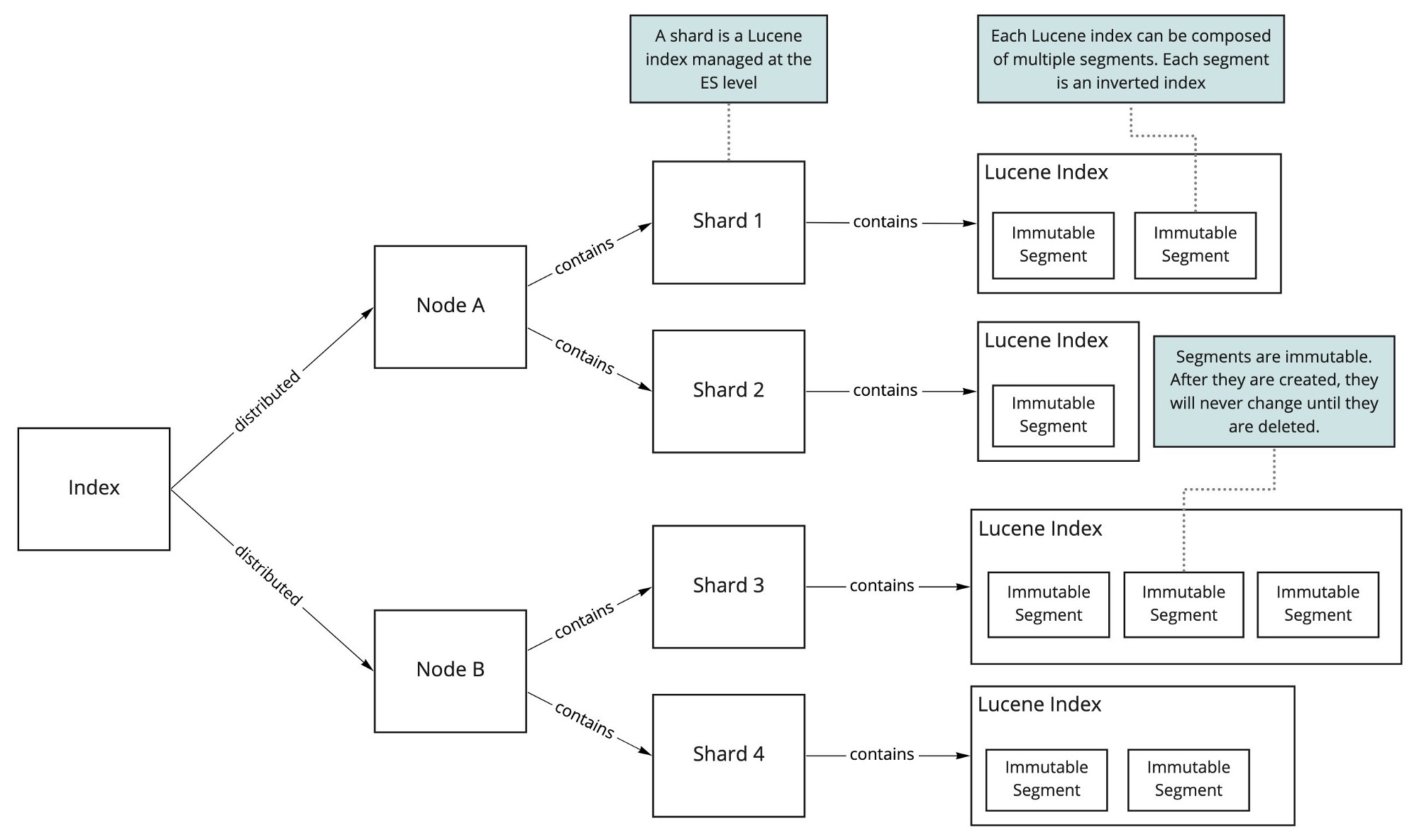
Index
هر ایندکس، مجموع های از اسناد است که دارای ویژگیهای تقریبا مشابه هستند و میتوانیم روی یک کلاستر تنها به تعداد دلخواه ایندکس داشته باشیم و هر ایندکس توسط نام خود شناسایی و تعیین میشود و برای انجام عملیات ایندکس، جستجو، حذف وبروزرسانی دانستن نام ایندکس ضروری است.
یک ایندکس میتواند حجم عظیمی از داده را ذخیره کند که از محدودیتهای سخت افزاری یک سرور تجاوز میکند. بطور مثال یک ایندکس شامل یک ملیارد سند، به فضایی در حدود 1TB جهت ذخیره سازی نیاز دارد که ممکن است بیشتر از ظرفیت یک سرور باشد و یا اگر هم امکان ذخیره سازی این حجم از داده را داشته باشد مدت زمان پاسخ به درخواستهای جستجو را به مراتب افزایش و در نتیجه باعث کاهش کارایی کلاستر میشود. لذا جهت رفع این مشکل ES توانایی تقسیم ایندکسها به چندین قسمت را دارد که هر قسمت یا تکه Shard نامیده میشود و در زمان تعریف ایندکس براحتی میتوان تعداد shard های مورد نیاز را تعیین کرد و هر Shard کاملا کاربردی و مستقل عمل میکند و میتواند روی هر نود کلاستر قرار بگیرد.
Document
یک سند واحد پایه اطلاعات است که میتواند ایندکس شود و اسناد در ES قابل تبدیل شدن به فرمت JSON [11] هستند.
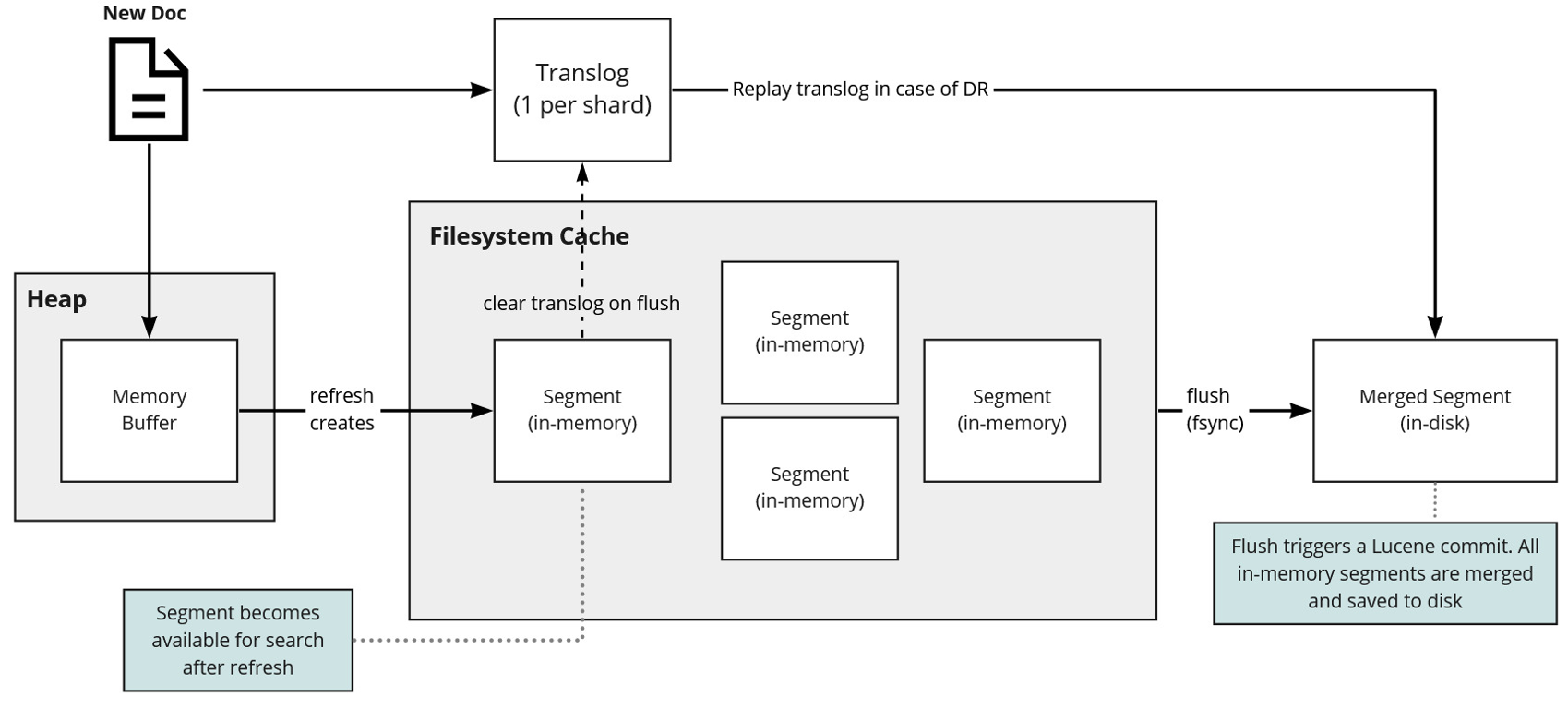
Shard & Replicas
یک ایندکس میتواند حجم عظیمی از داده را ذخیره کند که از محدودیتهای سخت افزاری یک سرور تجاوز میکند. بطور مثال یک ایندکس شامل یک ملیارد سند، به فضایی در حدود 1TB جهت ذخیره سازی نیاز دارد که ممکن است بیشتر از ظرفیت یک سرور باشد و یا اگر هم امکان ذخیره سازی این حجم از داده را داشته باشد مدت زمان پاسخ به درخواستهای جستجو را به مراتب افزایش و در نتیجه باعث کاهش کارایی کلاستر میشود. لذا جهت رفع این مشکل ES توانایی تقسیم ایندکسها به چندین قسمت را دارد که هر قسمت یا تکه Shard نامیده میشود و در زمان تعریف ایندکس براحتی میتوان تعداد shard های مورد نیاز را تعیین کرد و هر Shard کاملا کاربردی و مستقل عمل میکند و میتواند روی هر نود کلاستر قرار بگیرد.
Sharding به دو دلیل اصلی مهم است :
- حجم داده های روی Shard ها کم میشود و داده ها بین Shard ها تقسیم میشوند.
- امکان اجرای عملیات بصورت توزیع شده روی تمامی نودها فراهم میشود که در نتیجه باعث افزایش عملکرد/توان میشود.
در محیطهایی مانند بستر شبکه که در آن امکان شکست و Fail شدن سیستم در هر زمان را میتوان انتظار داشت بسیار توصیه میشود که یک مکانیزم Fialover جهت حفظ داده ها و کارایی سیستم وجود داشته باشد. به همین دلیل ES به شما اجازه میدهد تا یک یا چند کپی از هر Shard را روی یک سیستم دیگر به نام Replica Shard داشته باشیم.
یکی از دلایل مهم Replication :
- دسترس پذیری را روی Shard های Fail شده
خلاصه این بخش:
هر ایندکس میتواند داده های خود را روی چند Shard ذخیره کند. یک ایندکس میتواند چند و یا صفر Shard کپی داشته باشد .تعداد Shard ها و Replica ها میتواند در لحظه تعریف ایندکس تعیین شود و بعد از ایجاد ایندکس، فقط تعداد Replica ها قابل تغییر است. در ES و بصورت پیش فرض هر ایندکس روی 5 Shard اصلی ایجاد میشود و هر Shard اصلی یک Replica دارد. به طور مثال اگر کلاستر مورد نظر ما 2 نود داشته باشد، ایندکس شما شامل 5 Shard اصلی و 5 Shard Replica است. (جمعا دارای 10 Shard است) .
تنظیمات مورد نیاز جهت راهاندازی ES
تنظیمات مورد نیاز ES در دو فایل با نام های elasticsearch.yml و logging.yml انجام میشود و این دو فایل نیز در مسیر ES_HOME/config قرار دارند.
elasticsearch.yml
فایل elasticsearch.yml تنظیمات اصلی و پرکاربرد ES را دارا میباشد که در ادامه به موارد مهم و پرکاربرد آن اشاره میکنیم.
#cluster.name: elasticsearch
نام کلاستر ES را مشخص میکند که در حالت پیش فرض این نام elasticsearch تنظیم میشود.
#node.name: “Franz Kafka”
نام نود مورد نظر ES را تنظیم میکند و در حالت پیشفرض نام یکی از شخصیتها را به آن انتساب میدهد.
#node.master: true
نود اصلی یا کپی بودن را مشخص میکند. و در حالت پیشفرض نود را بصورت نود اصلی ایجاد میکند.
#node.data: true
امکان ذخیره سازی داده را به نود مربوطه میدهد. و در حالت پیشفرض این امکان به نود داده میشود.
#index.number_of_shards: 5
تعداد Shard های کلاستر را تعیین میکند که در حالت پیشفرض هر کلاستر با 5 Shard شروع بهکار میکند.
#index.number_of_replicas: 1
تعداد کپیها را از اطلاعات هر نود موجود در کلاستر را تعیین میکند که در حالت پیشفرض از هر نود یک کپی ایجاد میشود
#path.conf: /path/to/conf.
مسیر پوشه تنظیمات ES را مشخص میکند.
#path.data: /path/to/data
مسیر ذخیره سازی داده های ES را مشخص میکند.
برای اجرای ES به java 7 نیاز است که پیشنهاد خود ES، Oracle JDK Version 1.7.0 60 است و جهت بررسی نسخه جاوا میتوانید از دستور زیر در محیط ترمینال استفاده کنید:
Java –version یا echo $JAVA HOME
میتوانید آخرین نسخه ES را از آدرس زیر دانلود کنید :
http://www.elasticsearch.org/download
برای اجرای ES میتوانید فایل elasticsearch را از مسیر زیر اجرا کنید:
$ bin/elasticsearch
برای اجرا به صورت background میتوانید از روش زیر استفاده کنید:
$ bin/elasticsearch -d
در ادامه چند تنظیم ضروری ES جهت عملکرد بهتر را مورد برسی قرار میدهیم:
/etc/security/limits.conf:
elasticsearch – nofile 65535
elasticsearch – memlock unlimited
در این قسمت Xmx و Xms مورد نیاز ES را تعیین میکنیم. که با تعیین ES_HEAP_SIZE هر دو مقدار Xms و Xmx باهم برابر میشوند.
/etc/default/elasticsearch:
ES_HEAP_SIZE= 6G
MAX_OPEN_FILES=65535
MAX_LOCKED_MEMORY=unlimited
در این قسمت برای جلوگیری استفاده ES، از حافظه swapped اقدامات زیر را انجام میدهیم
/etc/elasticsearch/elasticsearch.yml:
bootstrap.mlockall: true
در محیط ترمینال سیستم :
sudo swapoff –a
البته امروزه الاستیک سرچ با ابزار گرافیکی کیبانا و نیز LogStash به یک مجموعه کامل مدیریت و مانیتورینگ لاگ ها و داده های سری زمانی هم تبدیل شده است و در نسخه های اخیر آن (نسخه ۵.۴) ، امکان استفاده از هوش مصنوعی در شناخت رفتارهای مخاطره آمیز در لاگ های ثبت شده هم به مجموعه قابلیت های آن اضافه شده است.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
[1] High Availablity
[2] Multi-Tenancy
[3] Document Oriented
[4] Conflict Management
[5] Per-Operation Persistence
[6] Scheme Free
[7] Open Source
[8] Full-Text Search
[9] Analytics
[10] Scalable
[11] Java Script Object Notation
Visits: 59140
برچسبLucene Solr آموزش ElasticSearch آموزش الستیک سرچ (Elastic Search) الاستیک الاستیک سرچ الستیک سرچ ایندکس متن سلر لوسین معماری الستیک سرچ (Elastic Search) موتور جستجو نشب و اجرای Elastic Search
نوشته های مرتبط




همچنین ببینید
خزشگر crawler4j و مقایسه با دیگر خزشگرها
در این نوشتار سعی داریم راه اندازی یک خزشگر وب قدرتمند را به همراه امکان …
4 دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

سلام و درود
آموزش فعال سازی token authentication کیبانا رو دارید؟ نیاز مبرم دارم!
خیلی خوب و کامل بود
سلام و درود بر همه مخصوصا استاد تاجبخش که خاطرات خوبی در دانشگاه صنعتی با ایشون داشتیم.
یک سوال خیلی مهم!
من نیاز دارم تا الستیک سرچ ۷.۳ رو کرک کنم تا بتونم از بعضی امکانات اضافیش استفاده کنم. ایا میتوانید در این زمینه کمک کنید؟
ممنون
اگر فقط امکان داره بصورت ایمیل به بنده اطلاع بدید . چون ممکنه لینک اینجا رو گم کنم و … ممنون
سلام من دانشجوی ارشد نرم افزار هستم. مطلبی که نوشته بودین برای من مفید بود. منون از انتشار… اگر فیلم آموزشی توی این زمینه دارید ممنون میشم به اشتراک بذارین…