 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
ویژگی نما های از پیش تولید شده یا Materialized view در کاساندرا
ویژگی ویژیگی نما های از پیش تولید شده در نسخه 3.0 کاساندرا و نسخه های بعدی از آن اضافه شده است. materialized view جدولی است که از داده های جدول دیگری با کلید اصلی و مشخصه های جدید ایجاد میشود. اما materialized view چه قابلیت هایی را برای ما ایجاد میکند؟
از دردسرهای کاساندرا برای کاربران تازه کار، این است که کاساندرا یک پایگاه داده مبتنی بر درخواست است یعنی بر اساس کوئری های SQL که برروی داده های در آینده اجرا خواهیم کرد، میبایست داده ها را ذخیره می کنیم. از طرفی نحوه بازیابی داده ها نیز، کاملا بسته به کلید اصلی (یا کلید پارتیشن) آن جدول دارد و روی فیلدهای غیر کلید، نمی توان پرسوجو و جستجو انجام داد. این نقطه ضعف موجب میشود که برای یک جدول خاص با کوئری های متفاوت، گاهی مجبور می شویم چندین جدول درست کنیم که داده های یکسانی را ذخیره می کنند منتها هر کدام در یک کیلد اصلی متفاوت دارند و برای یک کوئری خاص ایجاد شده اند و البته با سریعترین زمان ممکن به ما پاسخ می دهند ولی منابع ذخیره سازی ما را به شدت اشغال میکنند.
در کاساندرا، پرسوجوها با استفاده از تعریف کلید اصلی، قابلیت اجرا پیدا میکنند. به عبارتی اگر بخش where در عبارت select در هر پرسوجویی براساس کلیدهای اصلی متفاوتی باشد، در نسخه های پیش از 3.0، به اجبار میبایست یکی از دو راهکار زیر برای اجرای درخواست پرسوجو انتخاب شود:
(1) ایجاد یک جدول جدید با کلیدهای اصلی متفاوت که قابلیت پاسخ به درخواست پرسوجوی مورد نظر را برای ما ایجاد کن.
(2) استفاده از اندیس ثانویه برای فیلد مورد نظر که به این طریق قابلیت پاسخ به درخواست پرسوجوی مورد نظر را برای ما ایجاد کند.
برای مثال با فرض درخواست زیر (درخواست 1):
Select From user1 where user_id = 111 and birthday 2001 ? and birthday > ? 2018
جدول user1 با کلید پارتیشن user_id و کلید خوشه بندی birthday میتواند به پرسوجوی (درخواست 1) بطور بهینه پاسخ دهد:
Create table user1 ( user_id text, name text, birthday timeuuid, modify_time timeuuid, primary key(user_id,birthday) );
اکنون برای پاسخ به پرسوجو زیر (درخواست 2):
Select From user1 where user_id = 111 and name = Ali and birthday < 2012 ? and birthday > ? 2018
راهکار اول: ایجاد جدول جدید
میتوان جدولی جدید با کلید پارتیشن usr_id و کلیدهای خوشه بندی name و birthday ایجاد کرد:
Create table user2 ( user_id text, birthday timeuuid, name text, primary key(user_id, (name ,birthday)) );
- نقاط قوت این روش:
- کاساندرا میتواند بصورت بهینه به هر دو پرسوجوی پاسخ دهد (برای پاسخ به هر کدام از پرسوجوها دقیقا به جدول های متناظر هر کدام رجوع میکند).
- نقاط ضعف این روش:
- درج و بهنگام سازی برای داده های یکسان، باید برای دو جدول اعمال شوند.
- داده های یکسان، در دو جدول تکرار میشوند که البته با توجه به حصول کارایی بالا، میتوان از این ضعف، چشمپوشی کرد.
راهکار دوم: اسفاده از ایندکس ثانویه
میتوان بر روی ستون name در جدول user1، اندیس ثانویه اعمال نمود:
Create index name_idex on user1(name);
اکنون کاساندرا میتواند بدون اعمال ALLOW FILTERING به پرسوجوی (درخواست 2)، پاسخ دهد.
- نقاط قوت این روش:
- دیگر نیازی به ایجاد جدولی دیگر نیست و درنتیجه درج و بهنگام سازی، تنها در یک جدول (جدول user1) اعمال میشوند.
- نقاط ضعف این روش:
- امکان ایجاد شاخص در یک جدول، در نسخه های قبلی کاساندرا به آن اضافه شد و تاحدود زیادی مشکل فوق را حل می کرد اما به ازای هر نیاز جدید ، باید ایندکس جدید زده میشد یا جدولی جدید ساخته میشد و ساختار برنامه ها هم به تبع آن، گاهی نیازمند تغییر می شد .
- کاساندرا برای پاسخ به پرسوجوی (درخواست 2)، اگر فیلد user_id ذکر نشده باشد مجبور است تمام نودها را جستجو کند.
- در اینگونه از پرسوجوها که ALLOW FILTERING لازم است، به موجب همین نیاز کاساندرا مجبور است ابتدا تمام نتایج را انتخاب و سپس سطرهایی که مرتبط با birthday و name ) نیستند را پالایش یا حذف میکند. که این عمل حذف کردن کار پر هزینه ای شناخته می شود.
راهکار سوم: استفاده ویژیگی نما های از پیش تولید شده materialized view
اما در نسخه های سری 3.0 کاساندرا، میتوان از قابلیت materialized view بهره برد. این ویژگی در نسخه 3.0 کاساندرا و نسخه های بعدی از آن اضافه شده است. materialized view جدولی است که از داده های جدول دیگری با کلید اصلی و مشخصه های جدید ایجاد میشود.
View یا نما در یک بانک اطلاعاتی، یک دستور اس کیو ال ذخیره شده است که با هر بار فراخوانی، آن دستور اجرا شده و نتیجه اش به کاربر نمایش داده میشود و اما Materialized View یا نمای از پیش محاسبه شده ، نتایج ذخیره شده ی یک کوئری است که باعث می شود سرعت بازیابی اطلاعات بسیار بالا برود چون نیاز به محاسبه مجدد کوئری و انجام اتصالات و شرط ها نیست. نکته مهمی که در رابطه با نماهای محاسبه شده کاساندرا وجود دارد این است که با هر درج اطلاعات در جدول اصلی، این نماها هم به طور خودکار آپدیت شوند و ما نگران قدیمی بودن این نماها نخواهیم بود.
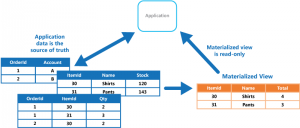
نسخه ۳ کاساندرا، با معرفی نماهای محاسبه شده، این امکان را می دهد که برای یک موجودیت خاص، کوئری های مختلفی در قالب نماهای محاسبه شده ذخیره شود و با آنها مانند یک جدول اصلی رفتار شود. یعنی دیگر نیاز به تعریف جدول های مختلف با ساختار یکسان برای یک موجودیت نخواهد بود.
create materialized view user_by_name as select * from user1 where name is not null and user_id is not null and birthday is not null primary key(name,user_id,birthday );
- نقاط قوت این روش:
- با هر درج اطلاعات در جدول اصلی، این نماها هم به طور خودکار آپدیت شوند و نگرانی قدیمی بودن این نماها وجود ندارد.
- دیگر نیاز به تعریف جدول های مختلف با ساختار یکسان برای یک موجودیت نخواهد بود.
- سرعت اجرا در مقایسه با استفاده از قابلیت ALLOW FILTERING بهبود پیدا میکند.
- نتایج از قبل محاسبه شده هستند.

آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 1552
برچسبapache Cassandra Materialized view view view در کاساندرا کاساندرا نما نما در کاساندرا نما در کسندرا نما های از پیش تولید شده نماهای از پیش محاسبه شده نمای از پیش ساخته شده
نوشته های مرتبط









همچنین ببینید
تجزیه گر یا پارسر متون و تشخیص زبان با آپاچی تیکا (Apache Tika)
آپاچی تیکا: آپاچی تیکا يکي از پروژههاي متن باز Apache است که کلاسي براي شناسايي …

انواع مجوزها یا لایسنس های مـتن بـاز (Open Source)
عناوين مطالب: 'بخش 1 مقدمه لایسنس های مـتن بـاز (Open Source)بخش 2 مجوزهای متن باز2-1مجوز …
