 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
تحلیل گراف های بزرگ با آپاچی فلینک (Apache Flink)
تعریف جریان داده: جریان داده ها، داده هایی هستندکه بطور مداوم توسط هزاران منبع داده تولید می شوند ، که معمولا رکورد های داده را به طور همزمان و در اندازه های کوچک (به ترتیب کیلوبایت) ارسال می کنند. داده های جریانی گسترده و متنوع هستند، مانند داده های ارسالی از دماسنج های یک منطقه ، فایل های گزارش( log file) استفاده از وب یا اپلیکیشن شما توسط کاربران ، خرید های تجارت الکترونیکی، اطلاعات شبکه های اجتماعی و …
عناوين مطالب: '
- پردازش گراف های عظیم با آپاچی فلینک ( Gelly API)
- مدل اجرای آپاچی فیلینک
- مقدمه :
- Gelly چیست؟
- پردازش تکراری گراف
- Gather-Sum-Apply
- راه اندازی آپاچی فلینک به صورت Standalone در دو حالت انجام می گیرد:
- نحوه راه اندازی آپاچی فلینک به صورت Standalone session mode در windows10:
- نحوه راه اندازی آپاچی فلینک به صورت Standalone session mode در Ubuntu
- Representation ↑
پردازش گراف های عظیم با آپاچی فلینک ( Gelly API)
فلینک یک چارچوب و موتور پردازش توزیع شده برای محاسبات برروی جریان داده های نامحدود و محدود است. جریان داه های نامحدود آغاز دارند اما پایانی ندارند به همین دلیل به محض اتفاق هررویداد باید بلافاصله پردازش شودکه این پردازش ها به ترتیب زمان اتفاق هر رویداد مرتب می شوند(پردازش جریانی).
جریان داده های محدود آغاز و پایانی معلوم دارند و می توان پس دریافت کامل داده ها، آن ها را پردازش نمود .ترتیب پردازش مهم نیست زیرا این داده ها قابل ذخیره سازی هستند(پردازش دسته ای).فلینک به گونه ای طراحی شده است که در همه محیط های خوشه ای رایج قابل اجرا میباشد، محاسبات را با سرعت حافظه و در هر مقیاس انجام دهد.[1]
بعبارت دیگر Apache flink یک پلتفرم پردازش داده توزیع شده برای استفاده در اپلیکیشن های بیگ دیتا(داده های حجیم) است که در درجه اول شامل تجزیه و تحلیل داده های ذخیره شده در خوشه های Hadoop است. فلینک با پشتیبانی از ترکیبی از پردازش در حافظه و مبتنی بر دیسک ، کارهای پردازش دسته ای و جریانی را کنترل می کند که پیاده سازی داده های جریانی را به صورت پیش فرض و کارهای دسته ای را هم به عنوان نسخه های خاص از اپلیکیشن های جریانی اجرا میکند.

نرم افزار فلینک منبع باز است و به مفاد مجوز بنیاد نرم افزار Apache پایبند است. توسعه آن اساسا توسط Data Artisans GmbH ، استارت آپ مستقر در برلین انجام می شود. برنامه های جریانی فلینک با API DataStream به وسیله زبان های جاوا یا Scala برنامه ریزی می شوند. از این زبان ها و همچنین پایتون می توان برای برنامه ریزی API مکمل دیتا ست برای پردازش داده های ثابت استفاده کرد.
فلینک را می توان روی یک ماشین مجازی جاوا (JVM) در حالت مستقل یا خوشه های Hadoop مبتنی بر YARN یا در سیستم های ابری مستقر کرد. هسته اجرای اصلی فلینک از معماری جریان خطی پشتیبانی می کند. همچنین یک روش داخلی برای پشتیبانی از پردازش داده های تکراری برای یادگیری ماشین و سایر برنامه های تحلیلی ارائه می دهد.
API ها و کتابخانه های اختصاصی برای توسعه برنامه های یادگیری ماشین و همچنین مدیریت رشته ها ، پردازش گراف ها و سایر موارد استفاده شده است. API دیگری نیزجهت ادغام برنامه Hadoop استفاده شده است. فلینک بعنوان شاخه ای از استراتوسفر به وجود آمد ، پروژه ای که در سال 2009 در سه دانشگاه آلمان آغاز شد: TU Berlin ، دانشگاه Humboldt برلین و موسسه Hasso Plattner. پس از آن فناوری فلینک در آوریل 2014 به یک پروژه اولیه Apache و در اواخر همان سال به یک پروژه سطح بالا تبدیل شد. پس از نه نسخه قبلی ، Apache فلینک 1.0.0 در مارس 2016 منتشر شد. با این کار ، فلینک رسماً به سایر چارچوب های اکوسیستم Hadoop مانند Spark ، Storm و Samza در رقابت پیوست تا قابلیت کار با جریان داده های بزرگ را فراهم کند.[2]
مقایسه آپاچی فلینک با دیگرابزار
فلینک برروی ویندوز و لینوکس قابل اجراست. برخلاف Sparkکه ذاتا یک موتور پردازش دسته ای است و یک API با عنوان streaming به آن اضافه شده تا بتواند داده ای جریانی را پردازش کند ، آپاچی فلینک بصورت بنیادی یک پردازشگر جریانی است و حتی داده های دسته ای را نیز با روش جریانی پردازش میکند.
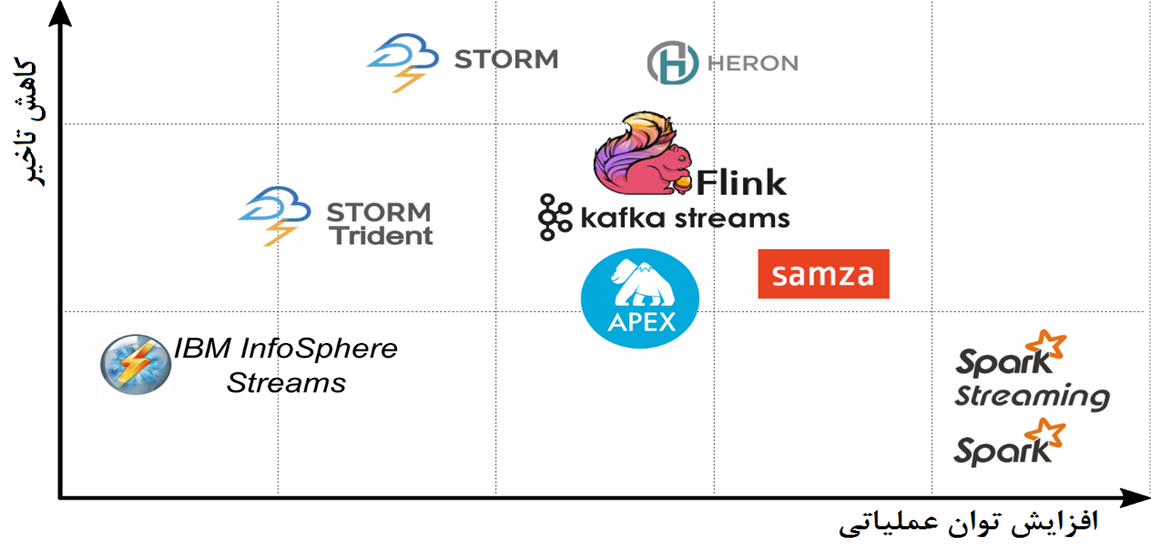
همانگونه که در شکل 1 مشاهده میکنید، آپاچی فلینک یک توازن بین سرعت و قدرت پردازش برقرارکرده است که این ویژگی آن را از سایر ابزارهای پردازشی بیگ دیتا متمایز نموده است.به طور مثال آپاچی اسپارک سرعت پایین تر اما توان عملیاتی بالاتری از فلینک دارد یا آپاچی استورم سرعت بیشتر اما توان کم تری دارد.
شکل1- مقایسه موتور های پردازش داده های عظیم
اکوسیستم آپاچی فلینک
همانگونه که درشکل 2 مشاهده میشود اجزای فلینک به شرح زیر میباشد:
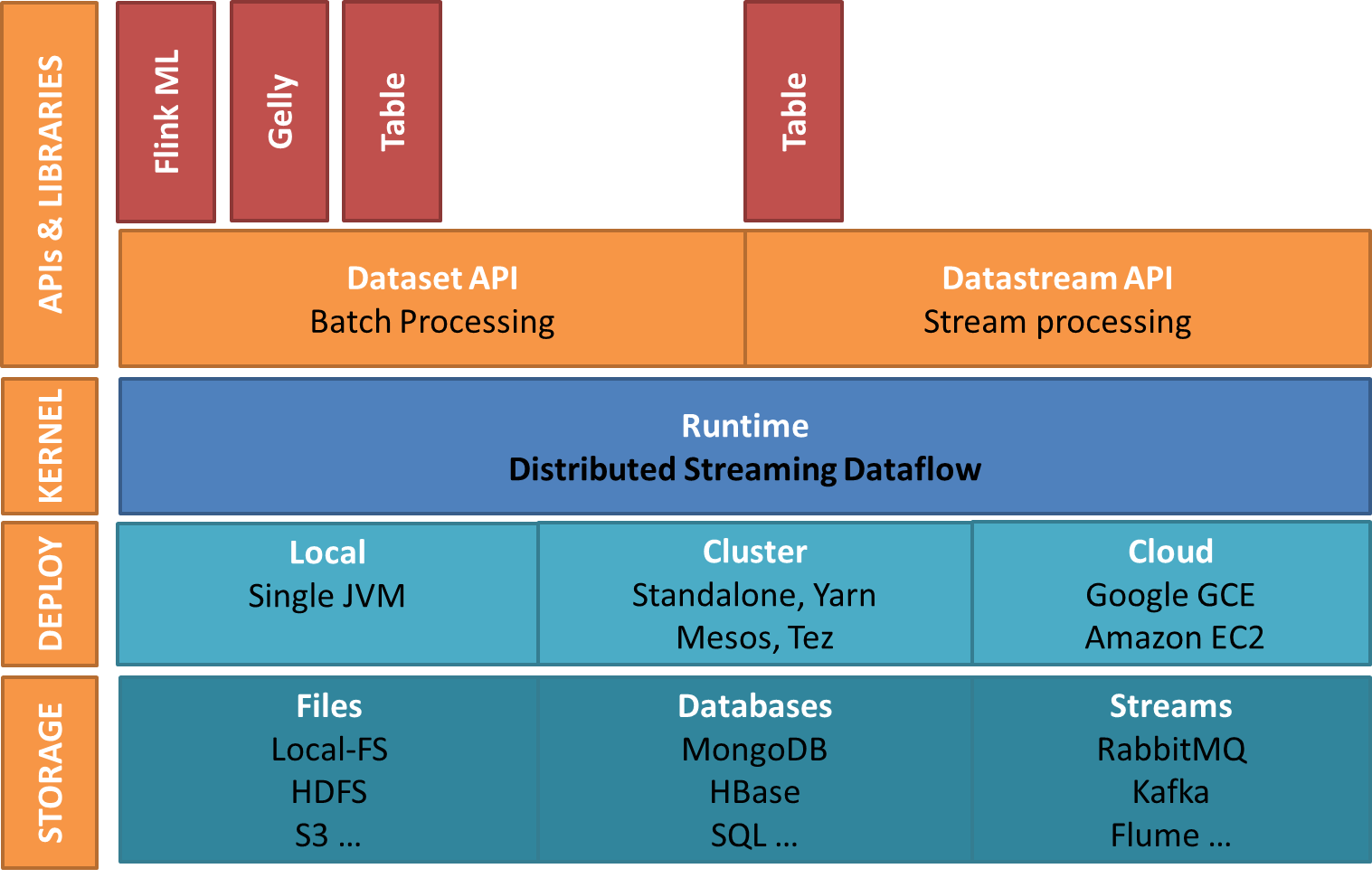
شکل2- اکوسیستم آپاچی فلینک
1-محل دخیره سازی
فلینک سیستم ذخیره سازی را همراهش حمل نمیکند و فقط یک موتور محاسباتی است. می تواند داده ها را از سیستم های ذخیره سازی مختلف بخواند ، بنویسد و همچنین می تواند داده های سیستم های جریانی را مصرف کند. ذخیره سازها به صورت زیر هستند:
الف – سیستم فایل ها
- HDFS : سیستم فایل توزیع شده Hadoop
- Local-FS : سیستم فایل محلی
- S3 : سرویس ذخیره سازی ساده از آمازون
ب – پایگاه داده ها
- HBase : پایگاه داده NoSQL در اکوسیستم Hadoop
- MongoDB : پایگاه داده NoSQL
- RDBMS : هر پایگاه داده رابطه ای
ج – ذخیره در سیستم های جریانی
- Kafka : صف توزیع شده پیام
- RabbitMQ : صف پیام رسانی
- Flume : ابزار جمع آوری وتجمیع داده ها
2-لایه توسعه : فلینک را می توان در حالت های زیر پیاده سازی کرد:
حالت محلی – در یک گره ، دریک JVM
حالت خوشه – در یک خوشه چند گره ، با هرکدام از مدیر منابع زیر:
- Standalone – این مدیر منابع پیش فرض است که با فلینک ارسال می شود.
- YARN – این یک مدیر منابع بسیار محبوب است که بخشی از Hadoop است که در Hadoop 2.x معرفی شده است
- Mesos – این یک مدیر منابع عمومی است.
حالت Cloud – در آمازون یا Google cloud
3 -لایه Runtime – روند داده (Dataflow) جریان توزیع شده که به آن هسته آپاچی فلینک نیز می گویند. درواقع لایه اصلی فلینک است که پردازش توزیع شده ، تحمل خطا ، قابلیت اطمینان ، قابلیت پردازش تکراری محلی و غیره را فراهم می کند.
4 -لایه API ها و کتابخانه است که قابلیت متنوع فلینک را فراهم می کند:
الف . دیتا ست API
داده ها را در حالت REST دستکاری می کند ، به کاربر اجازه می دهد عملیاتی مانند نگاشت ، فیلتر ، پیوند ، گروه بندی و غیره را روی مجموعه داده پیاده سازی کند. عمدتا برای پردازش توزیع شده استفاده می شود. در واقع ، این یک مورد خاص از پردازش جریان است که در آن یک منبع داده محدود داریم.مانند Table ، Gelly ، فلینکML
ب .DataStream API
یک جریان مداوم از داده ها را کنترل می کند. برای پردازش جریان داده های زنده ، عملیات مختلفی مانند نگاشت ، فیلتر ، حالت های بروزرسانی ، پنجره ، اجتماع و غیره را فراهم می کند. این APIمی تواند داده ها را از منبع مختلف جریان مصرف کند و می تواند داده ها را در سینک (منبع دریافت) های مختلف بنویسد. هم از جاوا و هم از اسکالا پشتیبانی می کند. مانند Table و CEP(پردازش رویداد پیچیده).
- Table Api : کاربران را قادر می سازد تا تجزیه و تحلیل موقت (add-hoc) را با استفاده از SQL مانند زبان ارائه[3] برای پردازش دسته ای وجریانی رابطه ای انجام دهند. در واقع ، کاربران را از نوشتن کد پیچیده برای پردازش داده ها نجات می دهد ، در عوض به آنها اجازه می دهد تا کوئری های SQL را درفلینک اجرا کنند.
- Gelly Api : یک موتور پردازش گراف است که به کاربران اجازه می دهد مجموعه ای از عملیات را برای ایجاد ، تبدیل و پردازش گراف اجرا کنند. Gelly همچنین کتابخانه ای از یک الگوریتم را برای ساده سازی توسعه اپلیکیشن های گراف فراهم می کند. از مدل پردازش تکراری بومی فلینک استفاده می کند تا گراف را به طور موثر اداره کند. API های آن در جاوا و اسکالا موجود است.
- فلینکML Api : یک کتابخانه یادگیری ماشین است که API های بصری و یک الگوریتم کارآمد برای مدیریت برنامه های یادگیری ماشین را فراهم می کند. آن را در Scala می نویسند. همانطور که می دانیم الگوریتم های یادگیری ماشین ماهیتی تکراری دارند ، فلینک پشتیبانی بومی را برای الگوریتم های تکراری فراهم می کند تا آن را کاملاً کارآمد مدیریت کند.[4]
معماری آپاچی فلینک
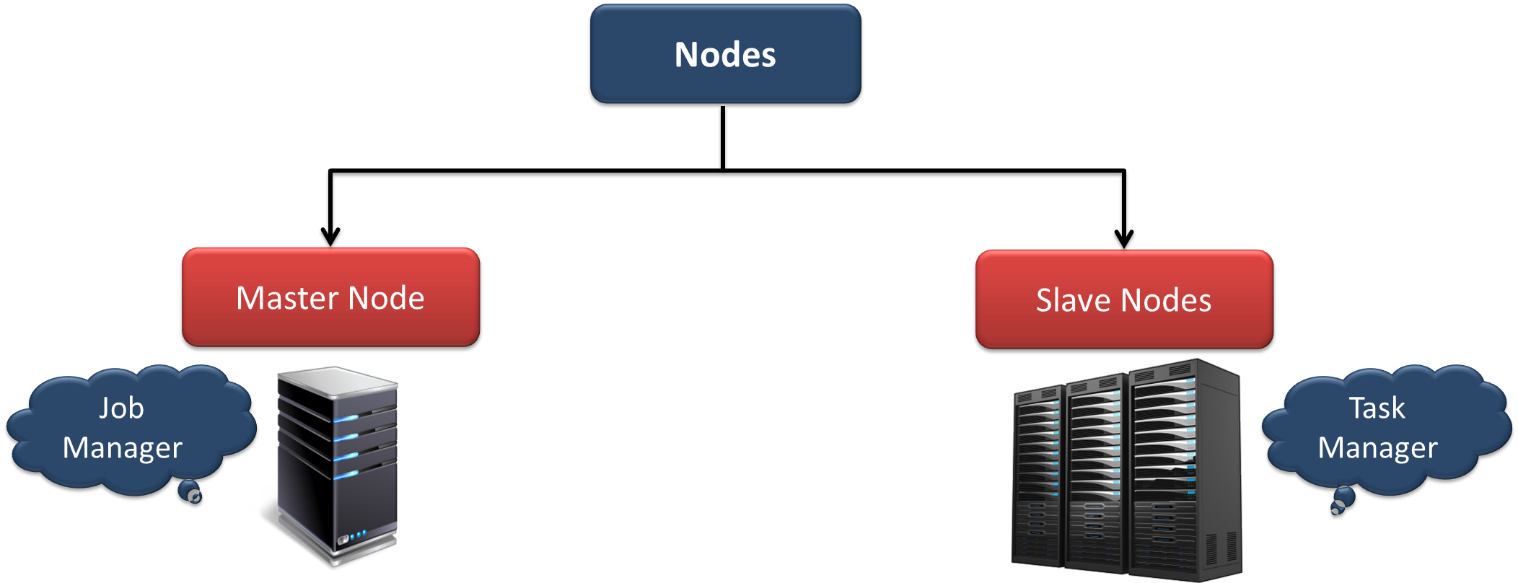
این سیستم از معماری Master/Slave بهره می برد.همانگونه که در شکل 3 مشخص است گره ها در این معماری به دو نوع تقسیم می شوند Master node که به آن Job Manager می گویند وSlave nodes که به آن ها Task Manager می گویند.همچنین نحوه ارتباط نودها درشکل 4 نشان داده شده است.
شکل3- انواع گره (node)های فلینک
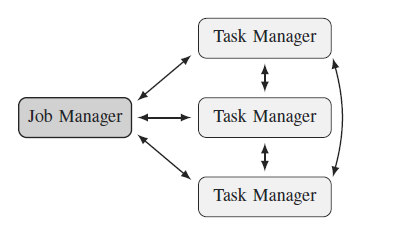 شکل 4 – نحوه ارتباط نودها در فلینک
شکل 4 – نحوه ارتباط نودها در فلینک
مدل اجرای آپاچی فیلینک
مدل اجرای فلینک در شکل 5 نمایش داده شده است. هرکدام از بخش های این مدل بشرح زیر میباشد:
Program (برنامه) : توسعه دهنده کد برنامه را نوشته است.
تجزیه و بهینه سازی : تجزیه کد ، استخراج نوع (Type Extractor) و بهینه سازی (Optimization) در طی این مرحله انجام می شود.
گراف DataFlow : هر کار به گراف جریان داده تبدیل می شود.
مدیر کار – مدیر کار وظیفه را بر عهده مدیران وظیفه می گذارد. فراداده جریان اطلاعات را حفظ می کند. مدیر کار اپراتورها را توسعه می دهد و نتایج میانی کار را کنترل می کند.
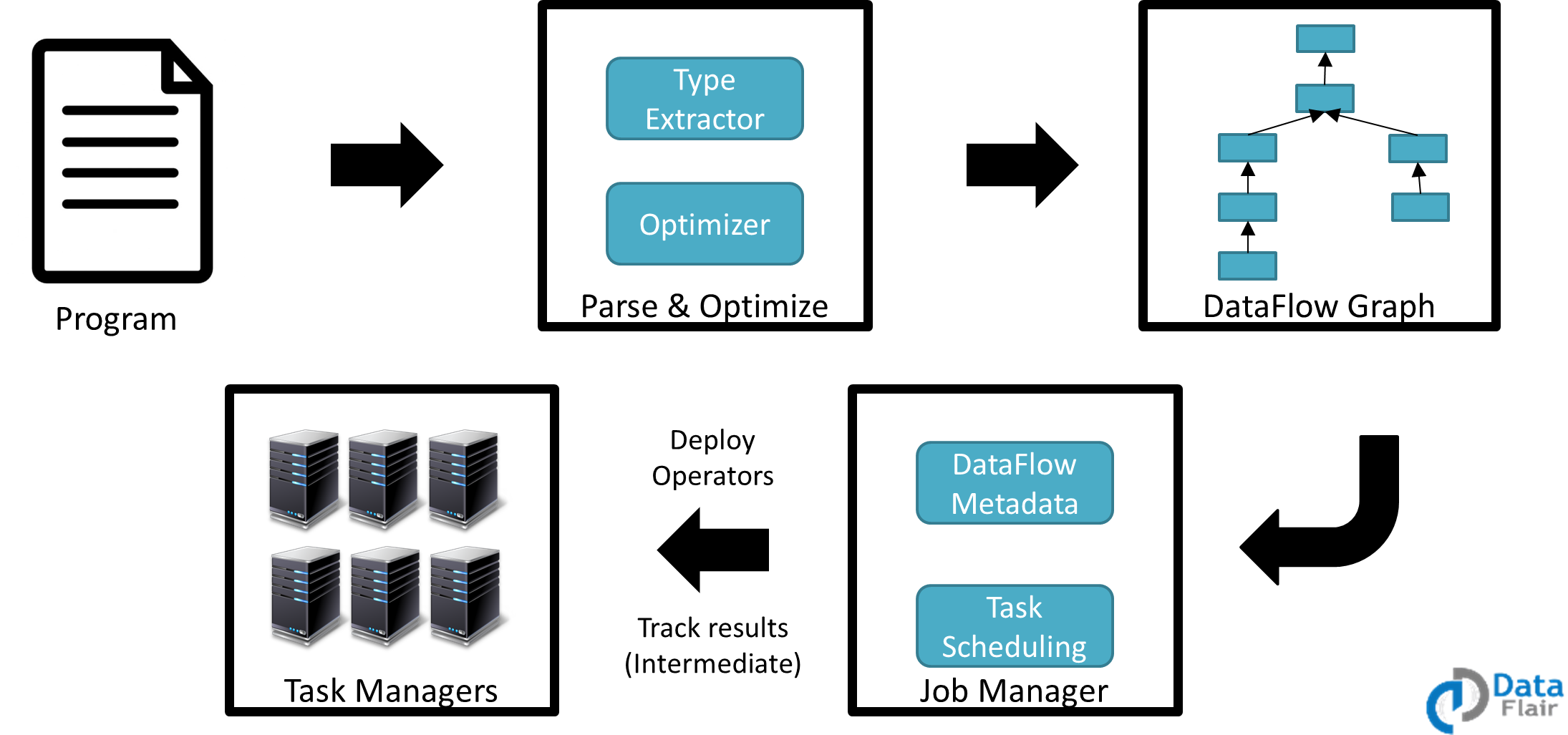
مدیر وظایف – وظایف روی مدیر وظیفه اجرا می شوند ، آنها گره های کارگر هستند.
شکل5-مدل اجرای فلینک
بررسی اجمالی Gelly :
- مقدمه
- Gelly چیست؟
- نمایش[5] و ایجاد گراف
- تبدیل ها و برنامه های کاربردی
- کتابخانه الگوریتم های پردازش تکراری گراف
مقدمه :
پشتیبانی بومی فلینک از تکرارها (iteration ) ، آن را به بستر مناسبی برای تجزیه و تحلیل گراف ها در مقیاس بزرگ تبدیل می کند. با استفاده از تکرارهای دلتا ، Gelly می تواند مدل های مختلف پردازش گراف مانند vertex-centric یا gather-sum-apply را بر جریان داده های فلینک نگاشت کند. Gelly به کاربران فلینک اجازه می دهد تا تجزیه و تحلیل داده های end-to-end را در یک سیستم واحد انجام دهند. این بدان معناست که پیش پردازش ، ساخت گراف، تجزیه و تحلیل و پردازش پس از آن را می توان در یک اپلیکیشن انجام داد.
Gelly چیست؟
Gelly یک Graph API برای فلینک است. این API شامل مجموعه ای از توابع ابزاری برای تجزیه و تحلیل گراف است ، از پردازش تکراری گراف پشتیبانی می کند و کتابخانه ای از الگوریتم های گراف را معرفی می کند. در حال حاضر با Java و Scala پشتیبانی می شود. متدهای Scala به عنوان wrapper ها برروی عملیات پایه ای جاوا پیاده سازی می شوند.شکل6.

شکل6- معماری فلینک و نقش Gelly
-
نمایش[6] و ایجاد گراف
در Gelly ، یک گراف با یک دیتا ست راس و یک دیتا ست از یال ها نمایش داده می شود. یک راس با شناسه منحصر به فرد و یک مقدار تعریف می شود ، در حالی که یک یال با شناسه منبع ، شناسه هدف و مقدار آن تعریف می شود. یک راس یا یال که مقداری برای آن مشخص نشده باشد ، به سادگی نوع مقدار را روی NullValue تنظیم می کند.
یک گراف را می توان با روش های زیر ایجاد کرد:
دیتا ست یال ها و دیتا ست های اختیاری رئوس با استفاده از ()Graph.fromدیتا ست
دیتا ست از Tuple3 و یک دیتا ست اختیاری از Tuple2 با استفاده از()Graph.fromTupleدیتا ست
مجموعه یال ها و یک مجموعه اختیاری از رئوس با استفاده از ()Graph.fromCollection .
در هر سه حالت ، اگر رئوس رانداشته باشیم ، Gelly به طور خودکار شناسه های رئوس را ازشناسه های منبع وهدف یال ها تولید می کند.
-
تبدیل ها و کاربردها
اینها متدهای کلاس Graph هستند و شامل معیارهای رایج گراف ، تبدیل ها ، جهش و همچنین تجمیع همسایگی هستند.
معیارهای رایج گراف
از این متدها ها می توان برای بازیابی چندین معیار و مشخصات گراف مانند تعداد راس ، یال ها و درجه گره استفاده کرد.
تبدیل ها
متد های تبدیل ، چندین عملیات گراف را با استفاده از توابع سطح بالا مشابه آنچه توسط API پردازش دسته ای ارائه شده ، فعال می کند. این تغییرات را می توان یکی پس از دیگری اعمال کرد و پس از هر مرحله گراف جدیدی ارائه داد ، به روشی مشابه عملگرها در دیتا ست s:
inputGraph.getUndirected().mapEdges(new CustomEdgeMapper());
تبدیل ها می تواند به موارد زیر اضافه شود:
- راس ها: mapVertices, joinWithVertices, filterOnVertices , addVertex …
- یال ها : mapEdges, filterOnEdges, removeEdge و…
- سه تایی ها : (source vertex, target vertex, edge): getTriplets
جمع آوری همسایه
روش های همسایگی به رئوس اجازه می دهد تا بر روی اولین هاپ (first-hop) همسایه خود به جمع بندی برسند که یک نمای vertex-centric ارائه می دهد ، جایی که هر راس می تواند به یال های همسایه و مقادیر همسایگی خود دسترسی پیدا کند.
()reduceOnEdges دسترسی به یال های همسایه یک راس ، یعنی مقدار یال و شناسه راس نقطه انتهای یال را فراهم می کند. برای دستیابی به مقادیر رئوس همجوار ، باید تابع ()reduceOnNeighbors را فراخوانی کرد. دامنه همسایگی توسط پارامتر EdgeDirection تعریف می شود ، که می تواند IN ، OUT یا ALL باشد ، تا یال های ورودی ، خروجی یا همه یال های (همسایگان) یک راس را جمع کند.
از دو تابع همسایگی که در بالا ذکر شد فقط زمانی می توان استفاده کرد که تابع تجمیع به صورت مشارکتی(associative ) و مبادله ای باشد. درصورتی که توابع با این محدودیت ها مطابقت نداشته باشند یا اگر صفر ، یک یا چند مقدار برای هر راس برگردانده شود ، باید توابع عمومی تر ()groupReduceOnEdges و ()groupReduceOnNeighbours را فراخوانی کرد.
برای مثال گراف زیر را در نظر بگیرید:
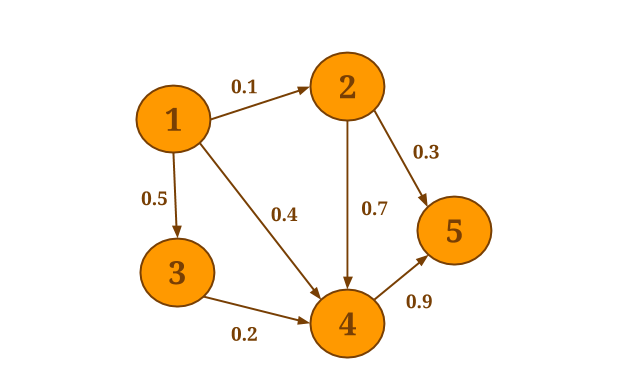
فرض کنید می خواهید مجموع مقادیر تمام همسایگان ورودی را برای هر راس محاسبه کنید. ما روش جمع آوری ()reduceOnNeighborsرا فراخوانی خواهیم کرد ، زیرا sum یک عمل به صورت مشارکتی (associative ) و مبادله ای است و مقادیر همسایگی ها مورد نیاز است:
graph.reduceOnNeighbors(new SumValues(), EdgeDirection.IN);
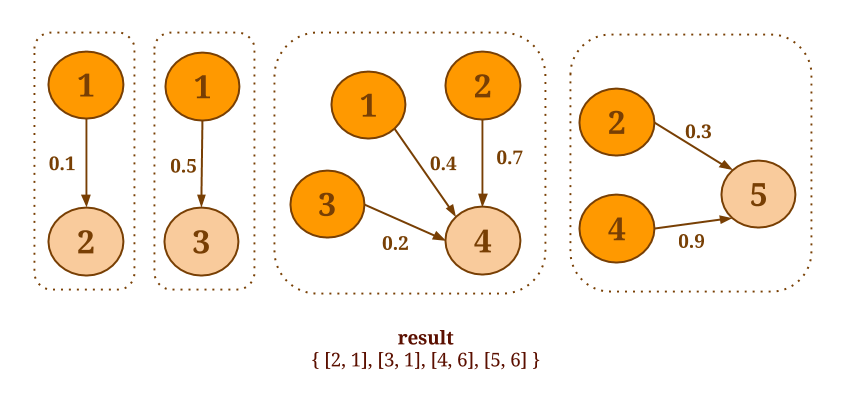
راس با id = 1 تنها گره ای است که هیچ یال ورودی ندارد. نتیجه به صورت زیر است:
پردازش تکراری گراف
طی چند سال گذشته ، مدلهای مختلف برنامه نویسی مختلفی برای پردازش گراف توزیع شده ارائه شده است: رأس محوری ، پارتیشن محوری ، جمع آوری-اعمال-پراکندگی ، یال محور ، همسایه محوری. هر یک از این مدل ها کلاس خاصی از برنامه های گرافیکی را هدف قرار داده و هر سیستم مربوطه به ترتیب، زمان اجرا را بهینه می کند. در Gelly ، ما می خواهیم از مدل جریان داده انعطاف پذیر و تکرارهای کارآمد فلینک برای پشتیبانی از چندین مدل پردازش گراف توزیع شده برروی این سیستم بهره ببریم.
در حال حاضر ، Gelly روش هایی برای نوشتن برنامه های vertex-centric دارد و از برنامه های پیاده سازی شده با استفاده از مدل gather-sum(accumulate)-apply حمایت می کند. ما همچنین در نظر داریم با استفاده از عملگر () Fink’s mapPartition پشتیبانی از مدل محاسبات پارتیشن محور را ارائه دهیم. این مدل ساختار پارتیشن را در معرض دید کاربر قرار داده و اجازه می دهد تا از ساختار محلی گراف در داخل یک پارتیشن استفاده کند تا از برقراری ارتباط غیر ضروری جلوگیری کند.
راس محور (Vertex-centric)
Gelly برای پشتیبانی از مدل برنامه نویسی راس محور و مدل برنامه نویسی Pregel-like ، Spargel APi فلینک را مشخص کرده است. متد runVertexCentricIteration متعلق به Gelly دو تابع تعریف شده توسط کاربر را می پذیرد:
- MessagingFunction: مشخص می کند که یک راس چه پیام هایی را برای مرحله بعدی ارسال می کند.
- VertexUpdateFunction: نحوه به روزرسانی راس بر اساس پیام های دریافتی را مشخص می کند.
این متد تکرار راس محور را بر روی گراف ورودی اجرا می کند و یک گراف جدید را با مقادیر راس به روز شده باز می گرداند.
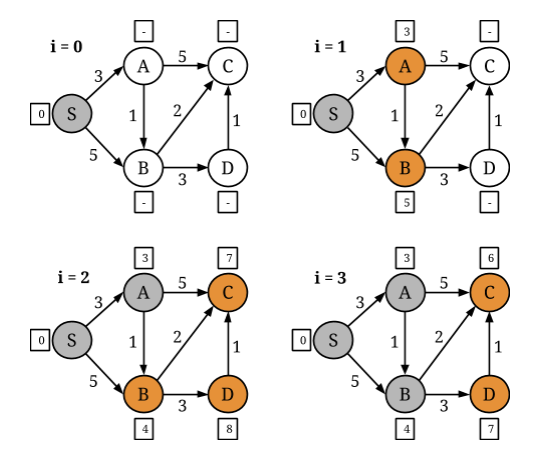
مدل برنامه نویسی راس محور Gelly از عملگرهای تکرار دلتا کارآمد فلینک بهره می گیرد. بسیاری از الگوریتم های نمودار تکرار شونده رفتار غیر یکنواختی را نشان می دهند ، به طوری که برخی از رئوس سریعتر از دیگران به مقدار نهایی خود می رسند. در چنین مواردی ، با رفتن الگوریتم به سمت همگرایی ، تعداد رئوس که باید در طی تکرار مجدداً محاسبه شوند ، کاهش می یابد. به عنوان مثال ، یک مسئله Single Source Shortest Paths را در گراف زیر در نظر بگیرید ، دراینجا S گره منبع است ، i شمارنده تکرار است و مقادیر یال فاصله بین گره ها را نشان می دهد:
در هر تکرار ، یک راس از همسایگان خود فاصله دریافت می کند و حداقل این فاصله ها و فاصله اخیرخود را به عنوان مقدار جدید تصویب می کند. سپس ، ارزش جدید خود را برای همسایگان خود منتشرمی کند. اگر یک راس در طی تکرار تغییر نکند ، دیگر نیازی به انتشارفاصله قدیمی خود تا همسایگان نخواهد بود.
اپراتور IterateDelta فلینک اجازه بهره برداری از این ویژگی و همچنین اجرای محاسبات را فقط روی قسمتهای فعال گراف می دهد. اپراتور دو ورودی دریافت می کند:
- Solution Set ، که نشان دهنده وضعیت فعلی ورودی است
- Workset ، که مشخص می کند کدام بخشهای گراف در تکرار بعدی محاسبه می شوند.
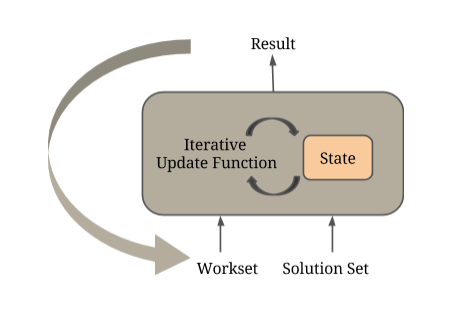
در مثال SSSP بالا ، Workset شامل رئوس است که فواصل خود را به روز می کند. تابع تکراری تعریف شده توسط کاربر برای تولید به روزرسانی حالت ، روی این ورودی ها اعمال می شود. این به روزرسانی ها به طور موثری بر روی حالت اعمال می شوند ، که در حافظه ذخیره می شود.
از نظر داخلی ، یک تکرار راس محور یک تکرار دلتا فلینک است ، که در آن مجموعه راه حل اولیه مجموعه راس گراف ورودی است و با انتخاب رئوس فعال ، Workset ایجاد می شود ، یعنی همان هایی که مقدار آنها را در تکرار قبلی به روز کرده است.
توابع پیامرسانی و به روزرسانی راس ، توابع تعریف شده توسط کاربر هستند که درون اپراتورهای coGroup قرار دارند. در هر مرحله فوق ، رئوس فعال (Workset) با یال ها گروه بندی می شوند تا همسایه های هر راس تولید شوند. سپس تابع پیام رسانی بر روی هر همسایه اعمال می شود. در مرحله بعد ، نتیجه تابع پیام رسانی با مقادیر راس فعلی (Solution Set) گروه بندی می شود و عملکرد به روزرسانی راس تعریف شده توسط کاربر روی نتیجه اعمال می شود. خروجی این عملگر coGroup در نهایت برای به روزرسانی مجموعه راه حل و ایجاد ورودی Workset برای تکرار بعدی استفاده می شود.

Gather-Sum-Apply
Gelly از تغییر مدل رایج محبوب Gather-Sum-Apply-Scatter که توسط PowerGraph معرفی شده پشتیبانی می کند. در GSA ، یک راس اطلاعات را از همسایگان خود می گیرد در حالی که رویه راس محور نیست ، به طوری که به روزرسانی ها از همسایگان ورودی گرفته می شود.
() RunGatherSumApplyIteration سه تابع تعریف شده توسط کاربر را می پذیرد:
- GatherFunction: مقادیر جزئی همسایه را در یال ها جمع می کند.
- SumFunction: مقادیر را به یک واحد جمع می کند یا کاهش می دهد.
- ApplyFunction: از نتیجه محاسبه شده در مرحله sum برای به روزرسانی مقدار راس فعلی استفاده می کند.
به طور مشابه راس محور ، GSA از عملگرهای تکرار دلتا فلینک استفاده می کند زیرا در بسیاری از موارد ، نیازی به محاسبه مقادیر راس در هنگام تکرار نیست.
کتابخانه الگوریتم های گراف
مجموعه کتابخانه ای از الگوریتم های گراف در Gelly است تا گراف های مقیاس بزرگ را به راحتی تجزیه و تحلیل کنیم. این الگوریتم ها رابط GraphAlgorithm را گسترش می دهند و می توانند با فراخوانی تابع ()run به راحتی روی گراف ورودی اجرا شوند.
Gelly در حال حاضر قابلیت پیاده سازدی الگوریتم های زیر را دارد:
- PageRank
- Single-Source-Shortest-Paths
- Label Propagation
- Community Detection (based on this paper)
- Connected Components
- GSA Connected Components
- GSA PageRank
- GSA Single-Source-Shortest-Paths
بیایید الگوریتم Single Source Shortest Paths را تجدیدنظر کنیم. در هر تکرار ، یک راس:
Gather : فاصله از همسایگان خود را جمع بندی شده با مقادیر یال مربوطه برمیگرداند.
Sum : فاصله های تازه بدست آمده را برای محاسبه کوچک ترین مقایسه می کند.
Apply : حداقل فاصله محاسبه شده در مرحله جمع را اعمال و در نهایت تصویب کنید ، به شرط آنکه کمتر از مقدار فعلی آن باشد. اگر مقدار راس در طی تکرار تغییر نکند ، دیگر فاصله خود را گسترش نمی دهد.
راه اندازی آپاچی فلینک به صورت Standalone در دو حالت انجام می گیرد:
- Session Mode
- Application Mode
نحوه راه اندازی آپاچی فلینک به صورت Standalone session mode در windows10:
- نصب جاوا Java 7.x or higherدانلود از لینک http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
- دانلود فلینک از http://flink.apache.org/downloads.html
- خارج کردن فایل فلینک از حالت فشرده
- رفتن به مسیر flink /binبا تایپ دستور cd flink /bin در cmd
- اجرای خوشه فلینک با تایپ دستور start-cluster.bat
- مشاهده داشبورد وب فلینک در آدرس localhost:8081
مثال: برنامه wordcount.jar که تعداد تکرار کلمات موجود در یک متن را محاسبه میکند، با استفاده از داشبورد وب فلینک قابل اجرا شدن است که نتیجه این برنامه را در cmd.exe قابل مشاهده است. پس از مراجعه به داشبورد فلینک مراحل زیر را طی کنید:
الف-آیتم Submit New Job و سپس گزینه ADD new را انتخاب کنید.
ب – از پوشه examples و قسمت streaming فایل wordcount.jar را انتخاب و سپس submitرابزنید .
ج – دراین مرحله dataflow graph به صورت ui نمایش داده می شود و پس از پایان پردازش تعداد تکرا رکلمات در یک متن را بعنوان خروجی به ما نمایش میدهد.
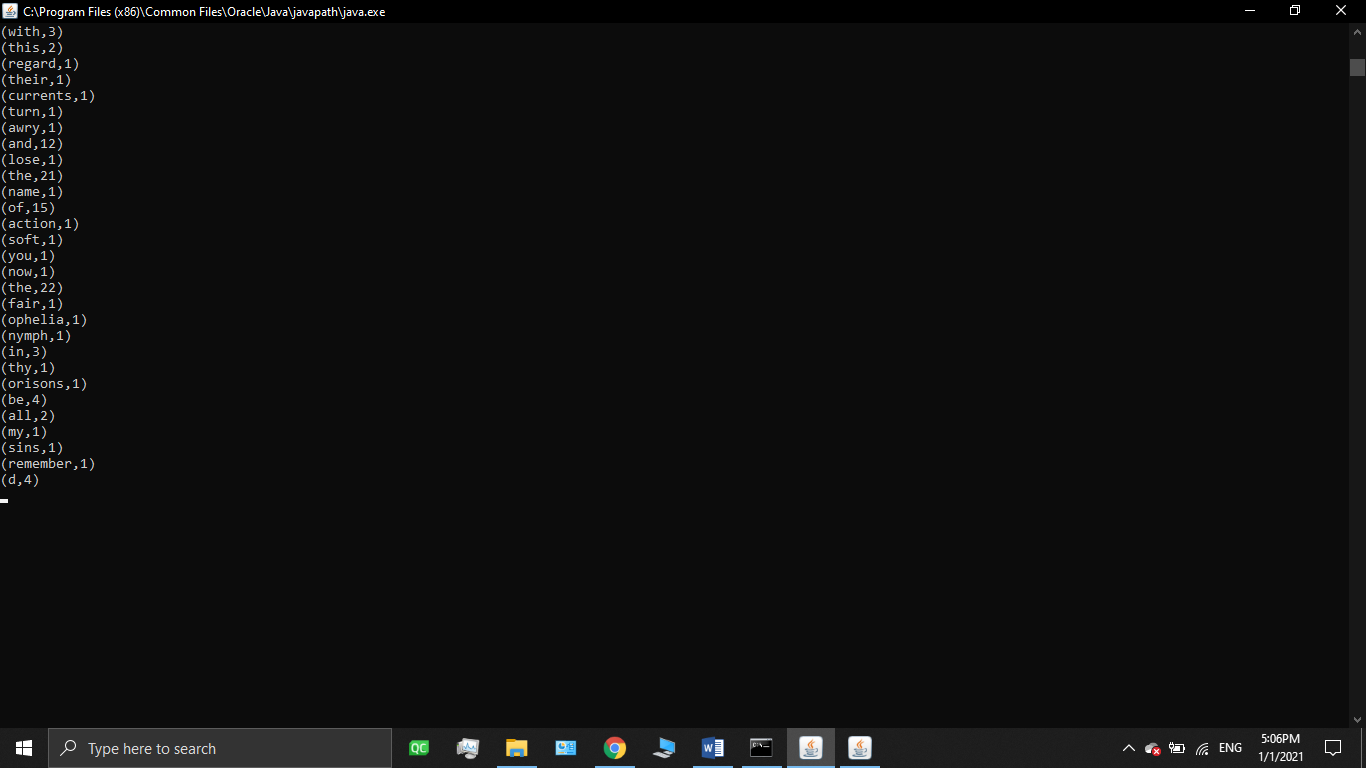
نحوه راه اندازی آپاچی فلینک به صورت Standalone session mode در Ubuntu
- نصب ابونتو
- نصب جاوا
- دانلود فلینک
- رفتن به پوشه bin
- اجرای خوشه فلینک با تایپ دستور start-cluster.sh/.
- اجرای دستورات زیر جهت اجرای برنامه wordCount و مشاهده خروجی در taskexecutor.out
- ./bin/flink run examples/streaming/WordCount.jar
- tail log/flink-*-taskexecutor-*.out
- مشاهده داشبورد وب فلینک در آدرس localhost:8081
- بستن خوشه فلینک
- ./bin/stop-cluster.sh
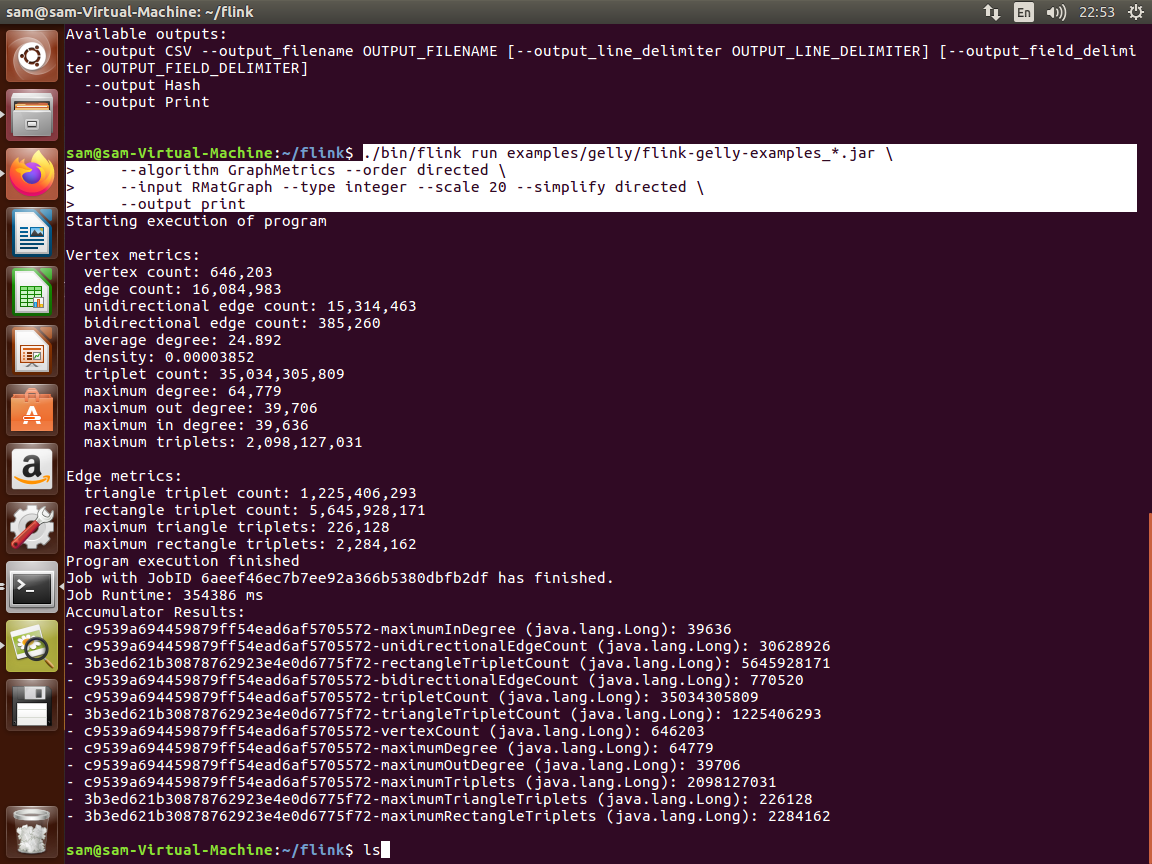
اجرای یک برنامه گراف gelly در فلینک به صورت standalone application mode (ابونتو)
همانگونه که درتصویر مشاهده میکنید مراحل 1 تا 3 به شرح زیر است:
مرحله 1 : رفتن به پوشه فلینک با دستور cd flink
مرحله 2: کپی کردن فایل flink-gelly_*.jar و flink-gelly_*.scala در lib

مرحله 3: start خوشه فلینک
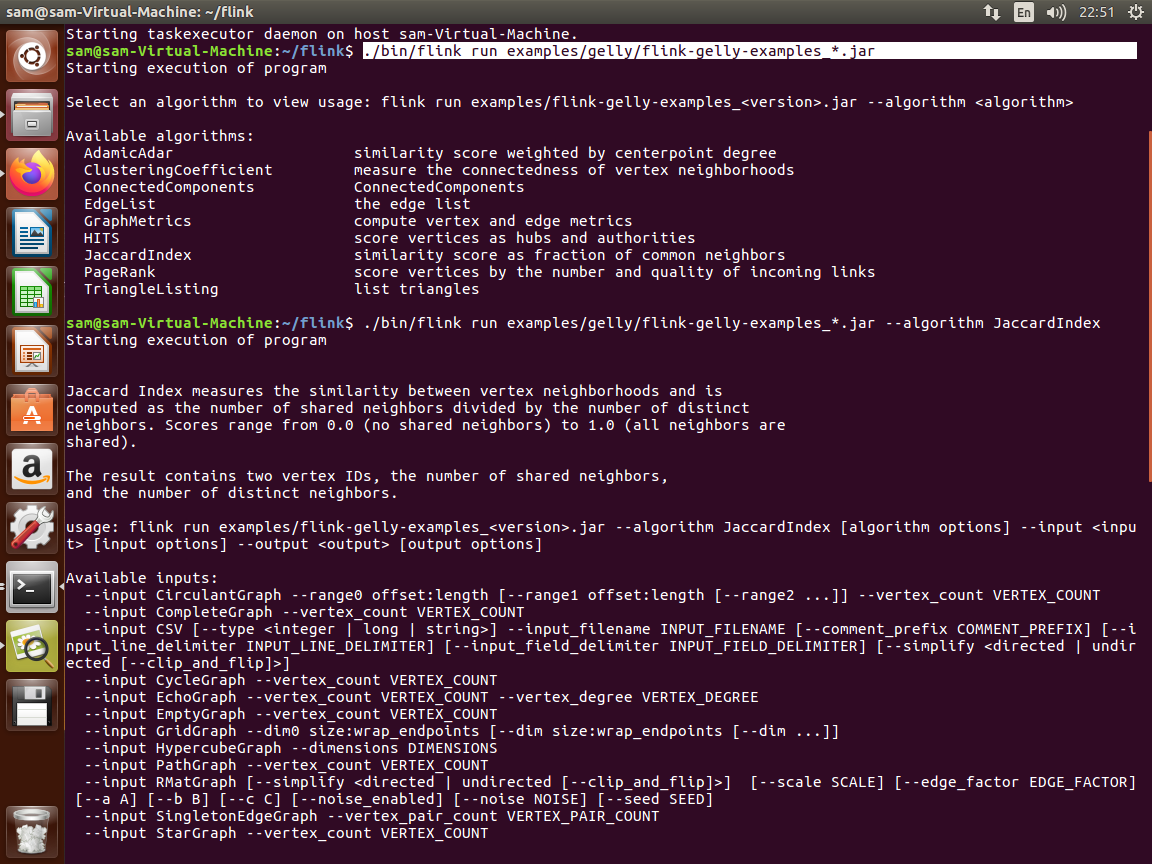
مرحله 4: run کردن مثال gelly
مرحله 5 و 6 و 7 : اضافه کردن الکوریتم مورد استفاده و فایل ورودی و نحوه نمایش یا ذخیره خروجی پردازش

منابع:
https://ci.apache.org/projects/ flink / flink -docs-stable/concepts/ flink -architecture.html#top
https://activewizards.com/blog/apache- flink -in-10-minutes
https://ci.apache.org/projects/ flink / flink -docs-release-1.2/dev/libs/gelly/index.html
https://ci.apache.org/projects/ flink / flink -docs-stable/dev/libs/gelly/
https://ci.apache.org/projects/ flink / flink -docs-stable/deployment/cli.html
https://ci.apache.org/projects/flink/flink-docs-release-1.12/try-flink/local_installation.html
پایان
-
https://فلینک.apache.org/فلینک-architecture.html ↑
-
https://searchdatamanagement.techtarget.com/definition/Apache-فلینک ↑
-
expression ↑
-
https://data-flair.training/blogs/flink-tutorial/ ↑
-
Representation ↑
تهیه کننده: صمدبیرانوند
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 1593
برچسبApache Flink apachi apachi filink Big Data Flink آپاچی فیلینک بیگ دیتا پردازش جریانی تحلیل گراف گراف کاوی گراف ها عظیم گراف های بزرگ
نوشته های مرتبط







همچنین ببینید

سطح بلوغ بیگ دیتا یا کلان داده حرکتی به سمت شرکت های داده محور
توسعه و اجرای استراتژی کلان داده برای سازمان ها کار آسانی نیست، به خصوص اگر …

دریاچه داده (Data Lake) چيست و چه تفاوتی با باتلاق داده (Data Swamp) دارد
دریاچه داده (Data Lake) و مفهوم بیگ دیتا دو واژه ناگسستنی هستند به عبارتی Data …
