خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
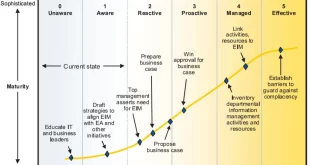
من بازخوردهای مثبت زیادی در مورد سری مدلهای بلوغ حاکمیت داده دریافت کردهام، زیرا نمای کلی هر مدل را در سطح بالایی ارائه میکند تا شما را در اتخاذ یکی برای برنامهتان راهنمایی کند. در این مقاله به مدل بلوغ حاکمیت داده می پردازم. …
ادامه مطلبانواع مدل های بلوغ حاکمیت داده چیست؟