 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
بخشبندی داده یا partitioning در پایگاه داده غیر رابطه ای کاساندرا
بخشبندی در پایگاه داده : در این مبحث در مورد قسمتبند یا بخش بندی (partitioning) کسندرا صحبت خواهیم کرد. قبل از شروع به توضیحات، اشاره ای به مبحث بخش بندی خواهیم نمود. به طور خلاصه وظیفه بخش بند، تقسیم داده ها به صورت تقریبا مساوی در کامپیوترهای متفاوت در یک خوشه است به نحوی که کم هزینه ترین روش خواندن و نوشتن بر روی داده ها به صورت اتوماتیک انجام شود. ضمن این که اندازه بخش ها تقریبا برابر باشد. آنچه که درک آن بسیار با اهمیت است این است که ما بدانیم که بین قابلیت بخشبندی و تکرار (Replication) تفاوت های اساس وجود دارد. بخشبندی روشی برای خرد کردن داده ها به قسمت های کوچکتر برای افزایش توان جستجو در داده ها و همچنین قطعه کردن داده ها به منظور عدم نیاز به ذخیره ساز های بزرگ تر است در صورتی که Replication روشی برای ایجاد نسخه بیشتر از یک داده ی یکسان به منظور افزایش سطح دسترسی پذیری و بهبود کارایی و تقسیم بار است. گاهی از بخشبندی نیز به عنوان partitioning نیز یاد میشود.
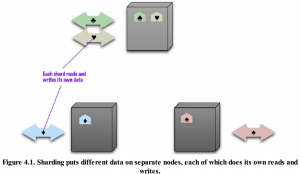
انواع بخشبندی در پایگاه داده کاساندرا
سه نوع قسمتبند یا بخشبندی در پایگاه داده کاساندرا قابل استفاده است که معمولا انتخاب بر اساس سیاست های سازمان است. که توسط مدیرسیستم تعیین شده و بعد از تعیین کسندرا به طور خودکار آن را بدون دردسر و کار اضافی برای مدیر پایگاه داد اعمال می کند. بهتر است قبل از عملیاتی شدن کسندرا بخشبند مطلوب مشخص شده باشد.
Murmur3Partitioner
Random Partitioner
Byte Ordered Partitioner
- قسمتبند Murmur3 : قسمتبند پيشفرض کسندرا بوده و بهترين و سریع ترین گزينه محسوب مي شود. اين روش از هش مخصوصی بدون قالبت رمز نگاری براي تعيين گرهي که يک سطر خاص را بايد ذخيره کند استفاده ميکند. این بخش بند سریع ترین بخش بند در بین بقیه است. اين روش از الگوریتم Murmur3 براي تعيين گره اي که يک سطر خاص را بايد ذخيره کند استفاده مي کند و 3 تا5 برابر کارایی را نسبت به نسخه های قبلی افزایش می دهد.
- با استفاده از الگوريتم Murmur، مقدار MurmurHash براي کليد سطر ايجاد ميشود (مقادير ممکن براي هش بين -2^63 و +2^63-1 است). گره اي اين سطر را ذخيره خواهد کرد که مقدار اين هش کمتر از مقدار رشته اش باشد.
- قسمتبند تصادفي : قسمتبند پيشفرض در نسخه های قدیمی بوده و بهترين گزينه در نسخه های سری 2 کسندرا محسوب ميشود. اين روش هم از هش براي تعيين گره اي که يک سطر خاص را بايد ذخيره کند استفاده مي کند.
با استفاده از الگوريتم MD5 ، مقدار هش MD5 براي کليد سطر ايجاد ميشود. (مقادير ممکن براي مقادير هش بين 0 و 127^2 است). گرهي اين سطر را ذخيره خواهد کرد که مقدار اين هش کمتر از مقدار رشتهاش باشد.
- قسمتبند ترتيبي : اين قسمتبند به دلايل مختلف از جمله موازنگي بار توصيه نميشود. مزيت اين قسمتبند اينست که براي مثال ميتوان سطرهايي را که کليد آنها بين اسم “حامد” و “حیدر” است را براحتي پيدا کرد. به عبارتي جستجوي محدوده در آن امکانپذير و سريع خواهد بود. انواع مختلف آن به صورت زير است:
- ByteOrderedPartitioner: سطرها به ترتيب بايتها (نمايش هگزادسيمال) ذخيره و قسمتبندي خواهند شد. براي مثال A معادل با 41 خواهد بود.
- OrderPreservingPartitioner: سطرها براساس مقدار کد UTF8شان مرتب و قسمتبندي خواهند شد.
- CollatingOrderPreservingPartitioner: سطرها براساس ايالات متحده انگليسي محلي! ذخيره خواهند شد.
منابع:
http://www.datastax.com/docs/0.8/cluster_architecture/replication
https://docs.datastax.com/en/cassandra/3.0/cassandra/…/archPartitionerAbout.html
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 1709
برچسبCassandra Partitioner partitioning sharding بخشبند بخشبندی داده بخشبندی در پایگاه داده بخشبندی در پایگاه داده کاساندرا بخشبندی کاساندرا بخشبندی کسندرا پارتیشن داده تقسیم بند تکه بندی داده خانواده ستون روش بخشبندی کسندرا ستونگرا شاردن شاردنینگ قسمت بند پایگاه داده
همچنین ببینید

پايگاه داده کاساندرا، روش نصب و بررسی نقاط ضعف و قوت
پايگاه داده کاساندرا یک سیستم انباره داده ی توزیعشده و کاملاً متن باز و رایگان …

مدل داده ای ستون گرا و تعریف شِمای مبتنی بر ستون در کاساندرا
پایگاه داده های ستون گرا به طور بالقوه می توانند به عنوان یک انبار داده …
