خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
مقایسه موتور جستجوی Solr و ElasticSearch
عناوين مطالب: '
مقدمه
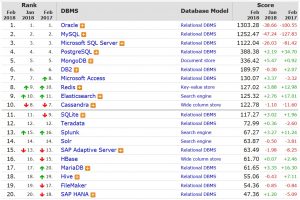
امروزه به علت گستره وسیع موتورهای جستجو و کارکردهای متفاوت آنها در حوزه های مختلف، انتخاب یک موتورجستجوی مناسب در راستای مرتفع کردن نیازمندی های مورد نظر مستلزم، مطالعه و مقایسه موتورجستجوهای موجود است. از این رو در این مبحث پیرامون مقایسه ی دو موتور جستجوی شناخته شده و مورد استفاده در بسیاری از پروژه های بزرگ با نام های Solr و ElasticSearch، توضیحاتی آورده شده است. این پست ابتدا به ویژگی های مطرح و بارز این دو محصول میپردازد و سپس در حوزه های مختلف آنها را مقایسه میکند. لازم به ذکر است که نسخه های مورد بررسی در این سند Solr 4 و ElasticSearch 1 میباشند. اگر به لیست بانکهای اطلاعاتی برتر دنیا هم در سایت db-engines نگاهی بیندازید، این دو جستجوگر متن را جزء بیست بانک اطلاعاتی مطرح امروزین خواهید یافت.
موتور جستجوی Solr
Solr یک موتور جستجوی بسیار معروف و مورد استفاده میباشد. این موتور جستجو متن باز بوده[1] و محصول تیم Lucene از شرکت Apache می باشد. ویژگی های مهم آن شامل جستجوکننده قدرتمند کاملا متنی[2]، ویژگی نشان دادن کلمات یافت شده درمتن[3]، ویژگی جستجوی وجهی[4]، شاخصگذاری[5] نزدیک به بلادرنگ[6]، خوشه بندی پویا[7]، یکپارچهسازی پایگاه داده[8]، بررسی انواع اسناد (بعنوان مثال: Word, PDF) غنی و جستجوی مبتنی بر اطلاعات جغرافیایی[9] میباشد. قابلیتهای غیرکارکردی Solr شامل اتکاپذیری بالا[10]، مقیاسپذیری و تحملپذیری خطا[11]، مهیا کردن شاخصگذاری توزیع شده[12]، رونوشت داده[13] و تنظیم بارگذاری[14] پرس و جوها[15]، تشخیص و بازیابی خودکار شکست خوردن سیستم[16] و پیکربندی متمرکز[17] میباشد. Solr در خیلی از سایتهای بزرگ دنیا مورد استفاده قرار میگیرد.
Solr به زبان جاوا نوشته شده است و میتواند یه صورت یک Servlet در بسترهای Servlet ها چون Jetty به صورت مجزا اجرا شود. این موتور جستجو از کتابخانه جستجوی جاوا Lucene بعنوان هسته شاخصگذاری و جستجو استفاده میکند و رابطهای استفاده در برنامهنویسی شبیه به REST HTTP/XML و رابطهای JSON کار با این موتور را از طریق هر زبان برنامه نویسی به طور مجازی برقرار کند. پیکربندی خارجی قدرتمند Solr اجازه پیاده سازی هر نوع برنامهای را بدون استفاده از جاوا و از طرفی معماری مبتنی بر افزونه این نرمافزار قابلیت پیشرفته سفارشی سازی را در زمان نیاز فراهم میآورد.
موتور جستجوی ElasticSearch
ElasticSearch(ES) یک موتور جستجو و تحلیل منعطف، قدرتمند، متن باز، توزیع شده، دسترسی بالا[18] و بلادرنگ میباشد که هسته شاخصگذار آن کتابخانه Lucene میباشد. از ابتدا به منظور استفاده در محیطهای توزیع شده بنا شده است، جایی که اتکاپذیری و مقیاس پذیری باید وجود داشته باشد، ES توانایی حرکت آسان ماوراء جستجوی کاملا متنی ساده را به شما میدهد. علاوه بر مجموع رابطهای برنامه نویسی تنومند[19] و درخواستهای DSL(Domain Specific Language )، همچنین رابطهای زبانهای برنامهنویسی معروف، ES وعده های بیحد و حصر استفاده از فناوری جستجو را ارائه میکند. علاوه بر قابلیتهای مذکور قابلیتهایی دیگری نیز قابل ذکر است از قبیل
- چندین شاخصی[20] : یک خوشه میتواند میزبان چند شاخصی که جدا از هم و یا به صورت یک گروه میباشند، باشد.
- مبتنی بر سند[21] : ذخیره سازی موجودیتهای پیچیده دنیای واقعی به صورت اسناد JSON انجام میگیرد. تمام فیلدها به صورت پیش فرض شاخصگذاری میشوند و تمام شاخصها در یک درخواست میتوانند استفاده شوند.
- مدیریت مغایرت[22] : یک کنترل کننده نسخه به منظور ممانعت از نابودی اطلاعات در زمان تغییرات همزمان
- رابطRESTful : استفاده از رابط RESTful به گونهای که از JSON بر روی پروتکل HTTP استفاده میکند.
- ماندگاری در هر عملیات[23] : برای ES در ابتدا امنیت داده مهم است. تغییرات اسناد در گزارشهای تراکنشها در چندین نود در خوشه مورد نظر ثبت میشود تا امکان از دست رفتن داده به حداقل برسد.
- عدم استفاده از قالب ثابت[24] : ES به صورت اتوماتیک ساختار داده مورد نظر را از اسناد JSON استخراج کرده و پس از شاخصگذاری آن را قابل جستجو قرار میدهد. سپس بعدها با اعمال دانش خاص منظوره دادههای شما، نحوه شاخصگذاری دادههای شما را تعیین میکند.

مقایسه دو موتور جستجوی Solr و ElasticSearch
هر دو موتور جستجوی Solr و ElasticSearch مبتنی بر هستهی Lucene ساخته شده اند، به همین علت ویژگیهای هسته آنها یکسان میباشد. این دو با استفاده از رابطهای برنامهنویسی Lucene ویژگیهایی را بر اساس آنها اضافه کرده و دسترسی به رابطها را به منظور استفاده در وب سرورها آسان کردهاست. در واقع تیم پیاده سازی به راحتی و با استفاده از دستورات HTTP به جای ارتباط مستقیم با Lucene و به دور از دغدغه زبان برنامه نویسی، شاخصها را ساخته و بر روی آنها جستجو میکنند. برای مقایسهی این دو موتور جستجو در ذیل جدولی ارائه شده است که شامل تفاوتهای مهم و تاثیرگذار آنها میباشد.
API
| Feature | Solr 6.2.1 | ElasticSearch 5.0 |
|---|---|---|
| Format | XML, CSV, JSON | JSON |
| HTTP REST API |  |
|
Binary API  |
SolrJ |
TransportClient, Thrift (through a plugin) |
| JMX support | |
 ES specific stats are exposed through the REST API ES specific stats are exposed through the REST API |
| Official client libraries |
Java | Java, Groovy, PHP, Ruby, Perl, Python, .NET, Javascript Official list of clients |
| Community client libraries |
PHP, Ruby, Perl, Scala, Python, .NET, Javascript, Go, Erlang, Clojure | Clojure, Cold Fusion, Erlang, Go, Groovy, Haskell, Java, JavaScript, .NET, OCaml, Perl, PHP, Python, R, Ruby, Scala, Smalltalk, Vert.x Complete list |
| 3rd-party product integration (open-source) |
Drupal, Magento, Django, ColdFusion, WordPress, OpenCMS, Plone, Typo3, ez Publish, Symfony2, Riak (via Yokozuna) | Drupal, Django, Symfony2, WordPress, CouchBase |
| 3rd-party product integration (commercial) |
DataStax Enterprise Search, Cloudera Search, Hortonworks Data Platform, MapR | SearchBlox, Hortonworks Data Platform, MapR etc Complete list |
| Output |
JSON, XML, PHP, Python, Ruby, CSV, Velocity, XSLT, native Java | JSON, XML/HTML (via plugin) |
Infrastructure
| Feature | Solr 6.2.1 | ElasticSearch 5.0 |
|---|---|---|
| Master-slave replication | Only in non-SolrCloud. In SolrCloud, behaves identically to ES. |
Not an issue because shards are replicated across nodes. |
| Integrated snapshot and restore | Filesystem | Filesystem, AWS Cloud Plugin for S3 repositories, HDFS Plugin for Hadoop environments, Azure Cloud Plugin for Azure storage repositories |
Indexing
| Feature | Solr 6.2.1 | ElasticSearch 5.0 |
|---|---|---|
| Data Import | DataImportHandler – JDBC, CSV, XML, Tika, URL, Flat File | [DEPRECATED in 2.x] Rivers modules – ActiveMQ, Amazon SQS, CouchDB, Dropbox, DynamoDB, FileSystem, Git, GitHub, Hazelcast, JDBC, JMS, Kafka, LDAP, MongoDB, neo4j, OAI, RabbitMQ, Redis, RSS, Sofa, Solr, St9, Subversion, Twitter, Wikipedia |
| ID field for updates and deduplication | |
|
| DocValues |
|
|
| Partial Doc Updates |
with stored fields |
with _source field |
| Custom Analyzers and Tokenizers |
|
|
| Per-field analyzer chain |
|
|
| Per-doc/query analyzer chain |
|
|
| Index-time synonyms |
|
Supports Solr and Wordnet synonym format |
| Query-time synonyms |
especially via hon-lucene-synonyms |
Technically, yes, but practically no because multi-word/phrase query-time synonyms are not supported. See ES docs and hon-lucene-synonyms blog for nuances. |
| Multiple indexes |
|
|
| Near-Realtime Search/Indexing |
|
|
| Complex documents |
|
|
| Schemaless |
4.4+ |
|
| Multiple document types per schema |
One set of fields per schema, one schema per core |
|
| Online schema changes |
Schemaless mode or via dynamic fields. |
Only backward-compatible changes. |
| Apache Tika integration |
|
|
| Dynamic fields |
|
|
| Field copying |
|
via multi-fields |
| Hash-based deduplication |
|
Murmur plugin or ER plugin |
Searching
| Feature | Solr 6.2.1 | ElasticSearch 5.0 |
|---|---|---|
| Lucene Query parsing |
|
|
| Structured Query DSL |
Need to programmatically create queries if going beyond Lucene query syntax. |
|
| Span queries |
via SOLR-2703 |
|
| Spatial/geo search |
|
|
| Multi-point spatial search |
|
|
| Faceting |
|
Top N term accuracy can be controlled with shard_size |
| Advanced Faceting |
New JSON faceting API as of Solr 5.x |
blog post |
| Geo-distance Faceting | |
|
| Pivot Facets |
|
|
| More Like This | |
|
| Boosting by functions |
|
|
| Boosting using scripting languages |
|
|
| Push Queries |
JIRA issue |
Percolation. Distributed percolation supported in 1.0 |
| Field collapsing/Results grouping |
|
|
| Query Re-Ranking |
|
via Rescoring or a plugin |
| Index-based Spellcheck |
|
Phrase Suggester |
| Wordlist-based Spellcheck |
|
|
| Autocomplete | |
|
| Query elevation |
|
workaround |
| Intra-index joins |
via parent-child query |
via has_children and top_children queries |
| Inter-index joins |
Joined index has to be single-shard and replicated across all nodes. |
|
| Resultset Scrolling |
New to 4.7.0 |
via scan search type |
| Filter queries |
|
also supports filtering by native scripts |
| Filter execution order |
local params and cache property |
|
| Alternative QueryParsers |
DisMax, eDisMax |
query_string, dis_max, match, multi_match etc |
| Negative boosting |
but awkward. Involves positively boosting the inverse set of negatively-boosted documents. |
|
| Search across multiple indexes | it can search across multiple compatible collections |
|
| Result highlighting | |
|
| Custom Similarity |
|
|
| Searcher warming on index reload |
|
Warmers API |
| Term Vectors API | |
|
Customizability
| Feature | Solr 6.2.1 | ElasticSearch 5.0 |
|---|---|---|
| Pluggable API endpoints |
|
|
| Pluggable search workflow |
via SearchComponents |
|
| Pluggable update workflow |
via UpdateRequestProcessor |
|
| Pluggable Analyzers/Tokenizers | |
|
| Pluggable QueryParsers |
|
|
| Pluggable Field Types | |
|
| Pluggable Function queries | |
|
| Pluggable scoring scripts | |
|
| Pluggable hashing |
|
|
| Pluggable webapps |
|
[site plugins DEPRECATED in 5.x] blog post |
| Automated plugin installation |
|
Installable from GitHub, maven, sonatype or elasticsearch.org |
Distributed
| Feature | Solr 6.2.1 | ElasticSearch 5.0 |
|---|---|---|
| Self-contained cluster |
Depends on separate ZooKeeper server |
Only Elasticsearch nodes |
| Automatic node discovery | ZooKeeper |
internal Zen Discovery or ZooKeeper |
| Partition tolerance | The partition without a ZooKeeper quorum will stop accepting indexing requests or cluster state changes, while the partition with a quorum continues to function. |
Partitioned clusters can diverge unless discovery.zen.minimum_master_nodes set to at least N/2+1, where N is the size of the cluster. If configured correctly, the partition without a quorum will stop operating, while the other continues to work. See this |
| Automatic failover | If all nodes storing a shard and its replicas fail, client requests will fail, unless requests are made with the shards.tolerant=true parameter, in which case partial results are retuned from the available shards. |
|
| Automatic leader election | |
|
| Shard replication | |
|
| Sharding |
|
|
| Automatic shard rebalancing |
|
it can be machine, rack, availability zone, and/or data center aware. Arbitrary tags can be assigned to nodes and it can be configured to not assign the same shard and its replicates on a node with the same tags. |
| Change # of shards | Shards can be added (when using implicit routing) or split (when using compositeId). Cannot be lowered. Replicas can be increased anytime. |
each index has 5 shards by default. Number of primary shards cannot be changed once the index is created. Replicas can be increased anytime. |
| Shard splitting | |
|
| Relocate shards and replicas |
can be done by creating a shard replicate on the desired node and then removing the shard from the source node |
can move shards and replicas to any node in the cluster on demand |
| Control shard routing |
shards or _route_ parameter |
routing parameter |
| Pluggable shard/replica assignment | Rule-based replica assignment |
Probabilistic shard balancing with Tempest plugin |
| Consistency | Indexing requests are synchronous with replication. A indexing request won’t return until all replicas respond. No check for downed replicas. They will catch up when they recover. When new replicas are added, they won’t start accepting and responding to requests until they are finished replicating the index. | Replication between nodes is synchronous by default, thus ES is consistent by default, but it can be set to asynchronous on a per document indexing basis. Index writes can be configured to fail is there are not sufficient active shard replicas. The default is quorum, but all or one are also available. |
Misc
| Feature | Solr 6.2.1 | ElasticSearch 5.0 |
|---|---|---|
| Web Admin interface | bundled with Solr |
Marvel or Kibana apps |
| Visualisation | Banana (Port of Kibana) | Kibana |
| Hosting providers | WebSolr, Searchify, Hosted-Solr, IndexDepot, OpenSolr, gotosolr | Found, Scalefastr, ObjectRocket, bonsai.io, Indexisto, qbox.io, IndexDepot, Compose.io, Sematext Logsene |
|
قابلیتهای مورد بررسی |
Solr 4 |
ElasticSearch 1 |
نتیجه بررسی |
|
Foundation |
· در سال 2008 میلادی منتشر شد. · با هدف پوشش ویژگیهای جدید جستجو بنا نهاده شد. · در سال 2012 با توجه به ویژگی جدید توزیع شدگی SolrCloud را منتشر کرد. |
· در سال 2010 میلادی منتشر شد. · با هدف پوشش ویژگی توزیع شدگی جستجو بنا نهاده شد. |
به دلیل هدف معماری ES و نحوه پیاده سازی آن راه اندازی یک خوشهی ES راحتتر و ساده تر از راه اندازی یک خوشه SolrCloud میباشد. |
|
Coordination |
· از ZooKeeper استفاده میکند. · به یک سرور مجزا برای ZooKeeper احتیاج دارد. · در هر Shard به یک رهبر احتیاج دارد. |
· از ZenDiscovery استفاده میکند. · فقط از نودهای ES استفاده میشود. · در مجموع به یک رهبر احتیاج دارد. |
برای راه اندازی SolrCloud علاوه بر راه اندازی Solr احتیاج به راهاندازی ZooKeeper نیز وجود دارد. در صورتی که برای راه اندازی ES به اجزاء دیگری احتیاج نیست. از طرفی هنگام کار با Solr درگیری تقسیمات فکری در خصوص مسائل خوشهها و نودهای آنها کمتر میباشد. |
|
Shard Splitting |
· Shard ها میتوانند در زمان اجرا اضافه و یا تقسیم شوند، اما نمیتوان تعداد آنها را کم کرد. · رونوشتهای داده را در هر زمان میتوان اضافه نمود. |
· نمیتوان تعداد Shardها را در زمان اجرا تغییر داد، اضافه و یا تقسیم کرد. · رونوشتهای داده را در هر زمان میتوان اضافه نمود. |
در این قابلیت که Solr حاوی آن میباشد. در زمانهایی که امکان تغییر نودها و Shardها وجود دارد استفاده از Solr بسیار توصیه میشود. زیرا در صورت استفاده از ES میبایست تمام اطلاعات دوباره شاخصگذاری شوند. |
|
Automatic Shard Rebalancing |
· چنین قابلیتی وجود ندارد. |
· با تنظیم مجزای تعداد نودها و تعداد Shardها و رو نوشتهای آنها از ابتدای فرآیند، در صورت تغییر نودها، جابجایی Shardها و رونوشت آنها به نودهای جدید به صورت خودکار انجام میپذیرد. |
در شرایطی که امکان افزایش تعداد Shardها در آینده به علت افزایش سختافزار وجود دارد، میتوان با افزایش تعداد Shardها در ابتدای فرآیند از پردازشهای احتمالی جهت تغییر Shardها جلوگیری کرده و در صورت افزایش نودها توازن بارگذاری و جابجایی Shardها و رونوشتها به صورت خودکار انجام میپذیرد. |
|
Scheme Creation And Scheme-Less Fields |
· ساخت قالب میبایست قبل از شاخصگذاری صورت گیرد و در زمان اجرا امکان پذیر نمیباشد. · میتوان در زمان اجرا فیلدهای با نوع پویا را علاوه بر قالب از پیش تعیین شده، شاخصگذاری کرد. · نمیتوان در هر قالب انواع متفاوتی در یک فیلد در نظر گرفت. |
· ساخت قالب بر اساس داده ورودی در زمان شاخصگذاری صورت میگیرد و نوع فیلدها به صورت خودکار تشخیص داده میشود. · میتوان در زمان اجرا فیلدهای با نوع پویا را علاوه بر قالب، شاخصگذاری کرد. · میتوان در یک قالب انواع مختلفی از یک فیلد را تعریف کرد. |
در صورتی که تغییرات دادهی مورد نیاز جهت شاخصگذاری بسیار کم باشد استفاده از قالب توصیه میشود و در غیر اینصورت هر دو موتور با توجه به تفاوت زمان ساخت قالب و تشخیص نوع فیلدها قابلیت تغییر در نحوه شاخصگذاری را ارائه میدهد. اما در صورتی که نوع داده ورودی و فیلدهای آن تغییرات داشته باشد به علت تشخیص خودکار و شاخصگذاری به هر نحو استفاده از ES توصیه میشود. |
|
Nested Typing |
· چنین قابلیتی وجود ندارد. |
· اسناد میتوانند شامل اسناد دیگری باشند. بعنوان مثال سند اطلاعات یک شخص حاوی سند آدرس خانه آن شخص نیز میتواند باشد. · در صورت استفاده نامناسب در صورت بروزرسانی و تغییر اسناد، تاثیر منفی در عملکرد شاخصگذاری دارد. · تمام اطلاعات کل سند در یک Shard باید بتواند ذخیره شود و ذخیره میشود. · میتوان اسناد والدین را براساس اسناد فرزندها مرتب کرد. · میتوان با استفاده از این اسناد و رابطه والدین و فرزندی عملیات الحاق را انجام داد. |
در صورت نیاز به عملیات الحاق و ارتباط والدین و فرندان بین اسناد میتوان از این نوع ساختار اسناد در موتور ES استفاده کرد. |
|
Query Syntax |
· بر مبنای کلید و مقدار و بصورت تو در تو (با استفاده از پرانتز) کار میکند. |
· با استفاده از JSON درخواستها ساخته و ارائه میشود. |
این بخش بستگی به میزان راحتی و آسانی استفاده کاربران از هر کدام از این دو نوع املاء درخواست دارد. |
|
Filters |
· میتوان از تجزیه کنندههای مختلف استفاده کرد. · میتوان از پارامترهای محلی استفاده کرد. · نتایج جستجوهای وجهی را تحت تاثیر قرار داده و در جهت هدف کاهش میدهد. |
· با استفاده از درخواستهای DSL تعریف میشود. · میتوان از آن در محاسبات امتیازدهی استفاده کرد. · نتایج جستجوی وجهی را تحت تاثیر قرار نداده و میزان آن را کاهش نمیدهد. |
بر مبنای استفاده کاربر وابسته است. هر کدام، قابلیتهای خود را دارا میباشند. |
|
Hash-Based Deduplication |
· این قابلیت به منظور استفاده از یک فیلد خاص به جای شناسه سند پیش فرض جهت حذف تکرار و یکتایی واقعی اسناد میباشد. |
· چنین قابلیتی وجود ندارد. |
این قابلیت به منظور استفاده در شرایطی چون زمانی که محتویات اسناد مختلف یکسان باشند و هدف یکتایی معنایی باشد به کار میآید. |
|
Plugins |
· میتوان در جریان کار جستجو و بروزرسانی استفاده کرد. · میتوان در انواع روشهای درهم سازی از آن استفاده کرد. |
· میتوان در جریان امتیازدهی از آن استفاده کرد. · میتوان در ارتباط با برنامههای تحت وب از آن استفاده کرد. · فرآیند خودکار نصب افزونهها |
بر مبنای استفاده کاربر وابسته است. هر کدام، قابلیتهای خود را دارا میباشند. |
|
Distributed Group By |
· این قابلیت در واقع دستهبندی زمینههایی چون مرتب کردن، فیلتر کردن، جستجوی وجهی و … به صورت توزیع شده انجام میدهد. |
· چنین قابلیتی وجود ندارد. |
در صورت نیاز به دسته بندی نتایج مختلف به صورت توزیع شده این قابلیت بسیار کاربردی میباشد. |
|
Percolation Queries |
· چنین قابلیتی وجود ندارد. |
· در این قابلیت موتور با ذخیره درخواستهای متنوع، در صورتی که اسناد ورودی در حوزهی پاسخ آن درخواستها باشد، اطلاع میدهد. · در صورت زیاد بودن درخواستهای ذخیره شده، عملکرد موتور در زمان شاخصگذاری کاهش مییابد. |
از این قابلیت در شرایطی که احتیاج به هشدار در صورت ورود سند خاص مد نظر باشد میتوان استفاده کرد. |
|
Pivot Faceting |
· انجام جستجوهای چند وجهی بر مبنای اولویتبندی وجوه میباشد و در واقع یک درخت تصمیم را شکل میدهد. |
· چنین قابلیتی وجود ندارد. |
از این قابلیت در جستجوهایی که چندین پارامتر از اسناد را همزمان بررسی میکنند و اولویت دستهبندی این پارامترها مهم میباشد، استفاده میشود. |
|
Histograms |
· چنین قابلیتی وجود ندارد. |
· این قابلیت نمودارهایی در بازههای زمانی و غیر زمانی مبتنی بر فیلدها در پاسخ به درخواست وجوه مورد نظر ارائه میکند. |
از این قابلیت برای ساختن نمودارهای متنوع و آماری از دادههای موجود در بازههای عددی و زمانی متفاوت استفاده میشود. |
|
Hadoop Integration |
· در خصوص ادغام و استفاده از Hadoop، تا این لحظه افزونه و یا نرمافزاری که با استفاده از Hadoop به پردازش محلی اطلاعات ذخیره شده در شاخص Solr بپردازد وجود ندارد. |
· در سایت مرجع ES، ادغام با Hadoop به عنوان یکی از ویژگیها و افزونههای این موتور جستجو در نظر گرفته شده است، به گونهای که میتوان اطلاعات ذخیره شده را به طور محلی بارگذاری و پردازش کرده و نتیجه را با استفاده از MapReduce گردآوری کرده و ارائه میکند. |
تا این لحظه فقط موتور ES این قابلیت را دارا میباشد. |
|
Distributed Replication |
· Solr پس از تایید در ساختن شاخص اسناد ورودی، پس از اینکه فایل یک تکه و به هم پیوسته شاخصها توسط Lucene تولید شد، آن را در نودها کپی میکند. |
· ES به جای آنکه فایل تولیدی را یکجا کپی کند، هر سند را به تمام نودها ارسال میکند و از آن کپی میگیرد. |
در Solr در صورتی که نرخ داده ورودی بسیار کم باشد و همه داده به یکباره شاخصگذاری شود خوب کار میکند و در صورتی که نرخ جریان داده متغیر باشد ES خیلی بهتر جواب میدهد. از طرفی هم در صورتی که یکی از نودها از خوشه حذف شود در موتور ES به علت کامل بودن تمام رونوشتها به راحتی نود مورد نظر جایگزین میشود. |
|
Users |
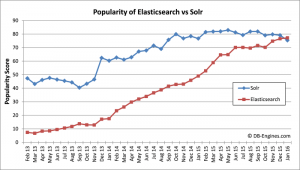
· Solr به علت قدمت بیشتر نسبت به ES از کاربرهای بیشتری برخوردار است و در نتیجه دارای مباحث و آموزشهای غنیتری نیز میباشد. |
· ES به علت نو ظهور بودن در عرصه موتورهای جستجو دارای کاربران کمتری میباشد ولی رشد فوق العادهای دارد. |
در حال حاضر Solr دارای کاربران بیشتری میباشد و بلاگها و مباحث بیشتری را پوشش میدهد. |
نتیجه گیری
با توجه به این که هسته شاخصگذار هر دوی این موتورهای جستجو Lucene میباشد، در بسیاری از ویژگی ها کاملا یکسان عمل میکنند. در بین ویژگی هایی که ذکر شد نقش فناوری جستجو و فناوری توزیع شدگی پر رنگتر از باقی نکات میباشد. در واقع باید این مطلب را اشاره کرد که هردوی این موتورها در راستای اهداف خود گام برداشته و موفق بودهاند. Solr با قابلیتهایی مرتبط با کیفیت جستجو و روشهای آن و نیز راحتی کاربر در استفاده از روابط کاربری تعبیه شده بسیار موفق بوده است. ES نیز با قابلیتهای مرتبط با آسانی راهاندازی توزیع شدگی و ادغام با نرمافزارهای مختلف علمی و پارامترهای مختلف خاص جستجو، با توجه به قدمت کمتر، بسیار موفق بوده است. از طرفی به علت پیشرفت روز افزون این محصولات در تمام عرصه ها تفاوتهای آنها در بخشهای مختلف پوشش خواهد داده شد. با وجود تمام این نکات انتخاب از بین این دو موتور جستجو بسیار وابسته به نیازمندیهای پروژه میباشد. در صورتی که توزیع شدگی و داده بسیار بزرگ و تجاری مد نظر میباشد ES انتخاب بهتری میباشد و در صورتی که پوشش انواع ارتباطات کاربری و جستجوهای خاص و یادگیری مد نظر باشد Solr گزینه مناسبتری میباشد.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
منابع :
http://solr-vs-elasticsearch.com
http://thinkbiganalytics.com/solr-vs-elastic-search
http://alexdong.com/one-fundamental-difference-between-elasticsearch-and-solr
http://db-engines.com/en/system/Elasticsearch%3BSolr
https://db-engines.com/en/blog_post/70
.https://sematext.com/blog/solr-vs-elasticsearch-differences/
آدرس کانال تلگرام ما:
t.me/bigdata_channel
برای ورود به کانال بر روی اینجا کلیک کنید.
[1] Open Source
[2] Full-Text Search
[3] Hit Highlighting
[4] Faceted Search
[5] Index
[6] Real-Time
[7] Dynamic Clustering
[8] Database Integration
[9] Geospatial Search
[10] High Reliability
[11] Scalable and Fault-Tolerant
[12] Distributed Indexing
[13] Replication
[14] Load-Balancing
[15] Queries
[16] Automated Failover and Recovery
[17] Centralized Configuration
[18] High Availablity
[19] Robust
[20] Multi-Tenancy
[21] Document Oriented
[22] Conflict Management
[23] Per-Operation Persistence
[24] Scheme Free
Visits: 21298
برچسبالستیک سرچ سلر سولر مقایسه Solr و ElasticSearch مقایسه موتور جستجوی مقایسه موتور جستجوی Solr و ElasticSearch موتور جستجوی ElasticSearch موتور جستجوی Solr