خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
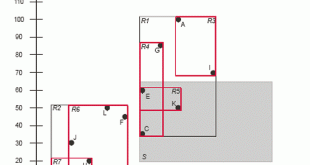
خلاصه سازی متن یا summarization، فشرده سازی متن به حالت کوتاهتر از متن اصلی است، به طوری که محتوای اطلاعاتی متن و به طور کلی مفاهیم کلی متن حفظ شود. به توجه به اینکه اسناد زیادی در اینترنت موجود است که بیشتر آنها محتوی …
ادامه مطلبخلاصه سازی متن یا summarization در حوزه متن کاوی