 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
فیلم آموزش آپاچی اسپارک به زبان ساده از شرکت لیندا
معرفی آپاچی اسپارک
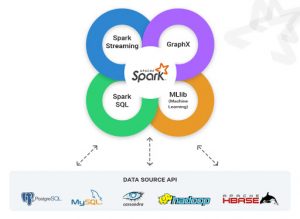
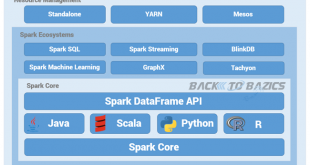
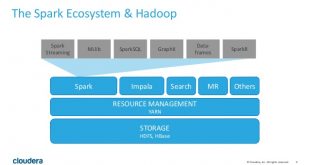
در پست های قبلی با معماری آپاچی اسپارک آشنا شدیم. اسپارک یک سکوی متن باز برای پردازش کلان داده است و در حال حاضر یکی از پروژههای موفق در بنیاد نرمافزار آپاچی میباشد. آپاچی اسپارک در ابتدا در سال 2009 در آزمایشگاه AMPLab شهر UC Berkeley توسعه داده شد و در سال 2010 به عنوان یک پروژه منبع باز آپاچی منتشر شد. آپاچی اسپارک دارای مزایای متعددی نسبت به سایر تکنولوژی های کلان داده مانند MapReduce مانند Hadoop و Storm دارد. اسپارک میتواند از سیستمهای مختلفِ ذخیرهسازیِ توزیع شده(مانند HDFS یا Cassandra) استفاده کند. اسپارک در مقایسه با هدوپ(Hadoop)، میتواند بسیار سریعتر باشد. همچنین آپاچی اسپارک به ما یک فریمورک جامع و یکپارچه برای مدیریت نیازهای پردازش داده های بزرگ با مجموعه های مختلفی از داده های متنوع (داده های متنی، نمودار داده ها و غیره) و نیز منبع داده را ارائه می دهد.
Spark با زبان برنامه نویسی Scala نوشته شده است و در محیط ماشین مجازی جاوا (JVM) اجرا می شود. در حال حاضر از زبان های زیر برای توسعه برنامه های کاربردی پشتیبانی می کند:
- Scala
- Java
- Python
- Clojure
- R
ویژگی های آپاچی اسپارک
- بهینه سازی مراحل جریان پردازش داده ها
- ذخیره سازی زیاد داده در حافظه
- پشتیبانی از نقشه و کاهش
- ارائه ی API های مختصر و سازگار در اسکالا، جاوا و پایتون
در ادامه می تواند فیلم آموزش آپاچی اسپارک به زبان ساده تولید شدخ توسط شرکت لیندا را دانلود کنید.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 2418
برچسبآپاچی آپاچی اسپارک اسپارک پردازش موازی داده های حجیم کلان داده
نوشته های مرتبط

همچنین ببینید

سطح بلوغ بیگ دیتا یا کلان داده حرکتی به سمت شرکت های داده محور
توسعه و اجرای استراتژی کلان داده برای سازمان ها کار آسانی نیست، به خصوص اگر …

دریاچه داده (Data Lake) چيست و چه تفاوتی با باتلاق داده (Data Swamp) دارد
دریاچه داده (Data Lake) و مفهوم بیگ دیتا دو واژه ناگسستنی هستند به عبارتی Data …
