 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
معماری پایگاه داده مانگو (MangoDB )
در این مبحث به توضیحات مختصصری در رابطه با معماری پایگاه داده مانگو در بخشبندی داده و نوزیع شدگی میپردازیم. در مباحث قبل با واحد های داده ای در MongoDB آشنا شدیم.
معماری پایگاه داده مانگو در روش بخشبندی
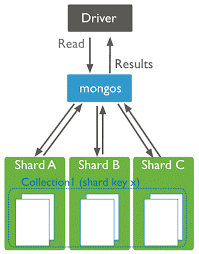
- Sharding: به معنی پردازش از طریق چندبخشی نمودن داده ها و ذخیره سازی هر بخش در یک ماشین جداگانه یا به عبارتی دیگر پارتیشنبندی اطلاعات. با استفاده از این روش دیگر نیازی نیست که برای داده های بزرگ یک ماشین بزرگ داشته باشیم بلکه با چند ماشین کوچکتر پردازش امکانپذیر است. ابتدا داده ها به اجزای کوچکتری به نام Chunk تقسیم میشوند. این Chunkها در Shardهای مختلف ذخیره میشوند که هر کدام از این Shardها مسئول یک بخش از داده ها میباشند. عملیات مسیریابی به کمک سیستم mongos صورت میگیرد. زمانی یک برنامه درخواستی از پایگاه داده میکنند این درخواست به mongos ارسال میشود و mongos درخواست را به همه Shardها ارسال میکنند و نتیجهها را ادغام نموده و به برنامه برمیگرداند. شایان به ذکر است که ساختار Shardها در config server ذخیره میشود.در MongoDB خاصیت Shard بهصورت اتوماتیک انجام میشود و این برتری سبب میشود که کار کردن با پایگاه داده های که بهصورت مستقل در چندین سرور متفاوت قرار دارند سادهتر شود.
روش تکثیر در معماری پایگاه داده مانگو
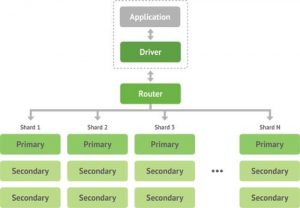
Replication: به این معنا میباشد که اطلاعات یک پایگاه داده بر روی چندین سرور دیگر نیز قرار میگیرد و به کمک روش های خاصی داده های سرور فرعی با سرور اصلی برابر میشود. به کمک این روش ترافیک سرور اصلی کمتر میشود و سرعت تهیه اطلاعات نیز بیشتر میگردد.
MongoDB دو پیادهسازی را در نظر گرفته است مدل Master-slave و Replica Set که در هر دو روش داده ها در سرور اصلی ذخیره شده و سرورهای فرعی به صورت غیر همزمان این اطلاعات را میخوانند. مکانیزم هر دو روش یکسان بوده و تنها تفاوت در این است که درروش Replica set با از کار افتادن نود اصلی یک نود فرعی جایگزین آن میشود و همچنین قدرت Recovery بهتری دارد. از این رو اجبار زیادی نسبت به استفاده از روش Master-slave نمیباشد.
روش تکثیر در معماری پایگاه داده مانگو
Map Reduce: یکی از ابزارهای aggregation میباشد که عملکردی مشابه با count group distinct دارد. همچنین این امکان را میدهد که عملیات به صورت موازی در چندین ماشین اجرا گردد. بدین صورت که مسئله به چندین قسمت تقسیم میشود و هر قسمت بهصورت جداگانه در هر ماشین اجراشده و نتیجهها ادغام میشوند. با یک مثال نحوه کارکرد این روش شرح داده میشود.
ابتدا با توجه به query اسناد مناسب انتخاب میشوند سپس با توجه به بخش map فیلدهای مورد نظر جدا میشوند. در قدم بعد برای کلیدهای که دارای مقادیر متعدد میباشند با توجه به بخش reduce مقادیر تجمیع میشوند و در نهایت خروجی در یک مجموعه ذخیره میشود.
برای جمعبندی اینگونه میتوان گفت که اگر انتظارات موردنیاز از یک پایگاه داده سرعت دسترسی و مقیاسپذیری (scalability) باشد پایگاه داده MongoDB انتخاب تقریبا مناسبی میباشد. اما در زمینهی سازگاری و یکپارچگی اطلاعات و امنیت دسترسی MongoDB انتخاب مناسبی نیست. همچنین قدرت طراحی پرسوجوهای پیچیده نیز بسیار ضعیف میباشد. اما همین ضعفها باعث شده که برای کار با داده های بزرگ مناسب باشد زیرا در قید محدودیت نبودن باعث شده سرعت پاسخدهی بالای داشته باشیم.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 2546
برچسبMongoDB Partitioner replication sharding پایگاه داده مانگو روش تکثیر سند گرا مانگو معماری MongoDB معماری پایگاه داده مانگو مقیاس پذیری
نوشته های مرتبط






همچنین ببینید

پایگاه داده BigchainDB معماری و نحوه عملکرد آن
پایگاه داده BigchainDB نرم افزاری است که دارای خصوصیات blockchain (به عنوان مثال عدم تمرکز …

مقایسه کاساندرا با پایگاه داده های غیر رابطه ای HBase, MongoDB, CouchDB, Neo4j
مقایسه کاساندرا با HBase, MongoDB, CouchDB, Neo4j در این مطالعه در دانشگاه Coimbra پایگاه دادههای …
