 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
درآمدی بر اسپارک (Spark) و بررسی معماری و اجزای آن
معماری اسپارک (Spark): این تکنولوژی، چارچوبی با کاربرد همه منظوره است و میتوان از آن برای انواع کاربردهای کلان داده، بخصوص شرایطی که سرعت عملیات از اهمیت ویژه ای برخوردار باشد، استفاده کرد. دو مثال از این کاربردها، تحلیل تعاملی و اجرای الگوریتم های پردازش تکراری است. در مبحث بعدی با نحوه کار با اسپارک آشنا خواهیم شد.
عناوين مطالب: '
الگوریتم های تکراری
الگوریتم های تکراری، الگوریتمهای پردازش دادهای هستند که بر روی یک مجموعه داده، چند بار تکرار میشوند. میتوان از الگوریتم های پردازش گراف (مانند گام تصادفی در PageRank) و یادگیری ماشین، به عنوان نمونه هایی از الگوریتم های تکراری نام برد. دلیل ایدهآل بودن Spark برای این گونه از الگوریتم ها، قابلیتهای پردازش مقیم در حافظه آن است. در Spark، الگوریتمی که نیاز به اجرای 100 تکرار بر روی یک مجموعه داده ای دارد، تنها در تکرار اول، داده ها را از دیسک و در تکرارهای بعدی، داده ها را از حافظه (cash شده اند) میخواند.
تحلیل تعاملی
تحلیل داده تعاملی، شامل کاوش بر روی مجموعه دادهای بصورت تعاملی است. برای مثال، ممکن است قبل از آغاز کار پردازشی دسته ای (که ممکن است ساعت ها بطول انجامد)، تحلیل مختصری بر روی مجموعه داده ای صورت گیرد (برای نمونه، فهمیدن تعداد خطوط یا تعداد موجودیت های مجموعه دادهای یا برخی از محاسبات آماری سبک). در این حالت، کاربر چند پرسوجو بر روی یک مجموعه داده ای اجرا میکند. توسط Spark، تنها اولین پرسوجو، دادهها را از دیسک و پرسوجوهای دیگر، داده ها را از حافظه میخوانند. ضمن اینکه کاربر میتواند توسط زبان پرسوجوی استاندارد SQL، پرسوجوهایی بر مجموعه داده ای (با فرمتهای مختلف از قبیل CSV، JSON، Parquet و DBMS ها) اجرا و نتیجه را بصورت تعاملی مشاهده کند
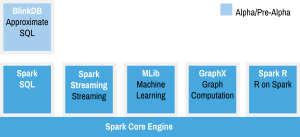
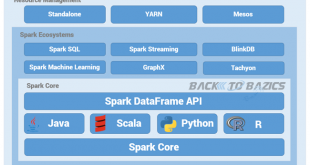
spark یک سامانه پردازش کلاستری همه منظوره و سریع می باشد. قبل از بررسی معماری اسپارک لازم است که با مؤلفه های اصلی آن آشنا شویم. این سامانه دارای چهار مولفه اصلی می باشد:
- MLib: این مولفه بستری را برای پیاده سازی الگوریتم های یادگیری ماشین فراهم می آورد. الگوریتم ها پیاده سازی شده در این مولفه در دسته های رده بند، کلاسترینگ، رگرسیون، پالایش همکارانه، کاهش بعد، و بهینه ساز قرار می گیرند.
- GraphX: این مولفه بستری را برای پیاده سازی الگوریتم های تحلیل گراف فراهم می آورد.لازم به ذکر است که هدف از چنین مولفه ای سرعت بالاتر برای پردازش گراف های عظیم می باشد.
http://ampcamp.berkeley.edu/5/exercises/graph-analytics-with-graphx.html
- Spark Streaming: یک توسعه از هسته اصلی Spark می باشد که قابلیت پردازش جریان های داده های زنده را با عمکرد مناسب و تحمل پذیری خطا دارا می باشد.
- Shark SQL: این مولفه این قابلیت را فراهم می کند که پرس و جوهای نوشته شده در SQL، HiveQL، و یا Scala با استفاده از spark اجرا شوند.
همانطور که در شکل زیر مشخص است این چهار مولفه برروی هسته spark پایه گذاری شده اند. لازم به ذکر است که هسته Spark عملگرهایی پایه ای را فراهم می کند که در هر مولفه می توان از آنها استفاده نمود.
معماری اسپارک
معماری اسپارک (Spark) یک معماری ارباب/برده یا کلاینت/سرور است و شامل پنج موجودیت اصلی زیر است:
بطور خلاصه، بخش اصلی برنامه راه انداز را برنامه کاربردی Spark مورد نظر تشکیل میدهد که در متد main آن، شیء SparkContext ساخته میشود (ابتدای برنامه های که قرار است در خوشه اجرا شود، شیء SparkContext ساخته میشود). Spark در دوحالت محلی (در یک ماشین) و خوشه (در چندین ماشین) اجرا میشود. راه انداز، در حالت خوشه، با مدیر خوشه ارتباط برقرار میکند و به محض اتصال، Spark، فرآیندهای مجری را در گره های خوشه ایجاد میکند که مسئول اجرای پردازش (وظایف) و ذخیره دادهها هستند. سپس، راهانداز، کد برنامه کاربردی (گرافی جهتدار و بدون دور که بیانگر عملیاتی است که باید اجرا شود) و وظایفی جهت اجرا را به فرآیندهای مجری ارسال میکند.
پیش از توضیح اجزای معماری اسپارک، به مفهوم اصطلاحات ذیل باید توجه کرد:
- application: که قرار است در خوشه اجرا شود. در ابتدای متد main این برنامه، شیء SparkContext ساخته میشود. SparkContext، منطق پردازشی را ذخیره میکند و میتواند مجموعهای از کارهای موازی یا سری را زمانبندی کند.
- job: مجموعه کاملی از تبدیلات روی RDD که با یک عمل action یا ذخیره سازی داده، خاتمه مییابد. در نتیجه، هر برنامه کاربردی، ممکن است شامل چندین کار باشد.
- stage: اسپارک هر کار را به گرافی از گامها تقسیم میکند. همچنین، هر گام شامل، مجموعه ای از وظایفی است که قابل اجرا توسط گره کارگر هستند.
Driver– راه انداز وظایف ذیل را برعهده دارد:
- مذاکره با مدیر خوشه جهت تخصیص منابع به کارگرها.
- هر کار را به DAG (گراف بدون دور جهت دار) ترجمه میکند.(Direct Acyclic Graph)
- گراف را به گامهایی تقسیم میکند. عملیات تبدیل در یک گام، و عملیات action در گام دیگر قرار میگیرند.
- وظایف را زمانبندی و اجرای آنها را کنترل میکند (بر اساس وضعیت کش جاری گرهها، مکانهای مطلوب و مناسب جهت اجرای هر وظیفه تعیین میشود).
Cluster manager:
راه انداز، قادر است تا به سه نوع مدیر خوشه (مدیر خوشه مستقل spark، Mesos یا Yarn) متصل شود و از آن درخواست منابع کند. هرکدام از این سه مدیر خوشه برای شرایطی خاص مناسب اند و میتوان یکی از آنها را برای مدیریت خوشه موجود انتخاب کرد. باید توجه داشت که مدیر خوشه مستقل Spark، بهمراه بسته Spark ارایه میشود، مدیر خوشه Yarn، نیز در پشته هادوپ و مدیر خوشه Mesos نیز چارچوب مستقل دیگری است. هر کدام از این سه مدیر خوشه، شامل دو بخش هستند:
(1) سرویس ارباب مرکزی (مدیر منابع Yarn، ارباب Mesos، یا ارباب مستقل Spark) که تصمیم میگیرد کدام فرآیندهای مجری، چه زمانی و در چه مکانی اجرا شوند.
(2) سرویس برده که در تمام گرهها اجرا میشود (مدیر گره در Yarn، برده در Mesos و برده در مدیر خوشه مستقل Spark) و فرآیندهای مجری را اجرا میکند و همچنین بر مصرف و حیات منابع آنها نظارت میکند.
executor:
در هر گره کارگر Spark، چند پردازش مجری وجود دارد (معمولا به اندازه تعداد هسته های گرهی برده، مجری ایجاد میگردد). هر برنامه کاربردی Spark، پردازشهای مجری خودش را دارد. هر مجری، مسئول موارد ذیل است:
- اجرای وظایفی که توسط راه انداز زمانبندی شدهاند، در چند نخ.
- ذخیرهسازی نتایج محاسبات در حافظه (کش کردن نتایج در heap ماشین مجازی جاوا) یا دیسک.
- تعامل با سیستمهای ذخیره سازی.
- پس از تکمیل اجرای وظیفه، نتایج را به راه انداز ارسال میکنند.
workers:
در معماری اسپارک، گره های برده بهعنوان گره کارگر شناخته میشوند که برای برنامه Spark، CPU، حافظه و منابع ذخیرهسازی فراهم میکنند.
tasks :
وظیفه، کوچکترین واحد کار است که Spark آن را به یک مجری ارسال میکند. هر وظیفه توسط نخی در یک مجری اجرا میشود. Spark، وظیفهای به ازای هر پارتیشن داده ایجاد میکند. مجری، ممکن است یک یا چند وظیفه را بصورت همروند اجرا کند. همانطور که واضح است، درجه موازی سازی، توسط تعداد پارتیشنها تعیین میشود.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بخشی عمده ای از مطالب معماری اسپارک را از وبلاگ دوست محترمم آقای نعمت پور با کمی ا اصلاح و تغییر در این پست کپی نموده ام.
Visits: 7049
برچسبSpark آموزش Spark آموزش اسپارک اسپارک پردازش موازی تحلیل دیدگاه مفهومی اسپارک معماری معماری Spark معماری اسپارک مفاهیم اسپارک
نوشته های مرتبط


همچنین ببینید
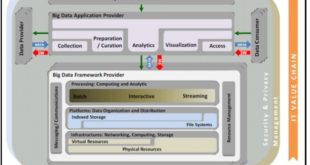
مدل مرجع معماری بیگ دیتا NBDRA (ISO 20547-3)
به بیان ساده، بیگ دیتا مجموعه داده های بزرگ و پیچیده تری هستند، که از منابع …
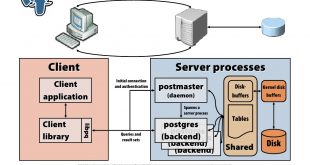
آموزش پایگاه داده PostgreSQL (معماری اجزاء و زیر سیستم ها )
عناوين مطالب: 'مقدمه ای بر دیتابیس PostgreSQLپردازندهی پرسوجو/فرمان در پایگاه داده PostgreSQL فهرست مراحل برای …
