 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
دادههای سری زمانی و پایگاه داده TimescaleDB
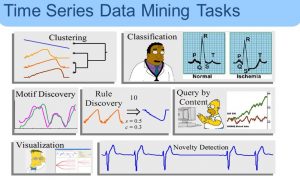
داده های سری زمانی یکی از مهم ترین انواع داده در حوزه داده کاوی محسوب می شوند. در سالهای اخیر، حجم دادههای سری زمانی به شدت توسعهیافته و نیاز به ابزارهایی برای مدیریت دادههای سری زمانی، در این مقیاس، بیش از پیش احساس میشود.
عناوين مطالب: '
مقدمه بر پایگاه داده TimescaleDB
تاکنون بیشتر ابزارهای تولید شده برای ذخیره و پردازش دادههای سری زمانی، مبتنی بر مدلهای دادهای NoSQLبوده است. دیتابیسهای غیررابطهای مختلفی توسعه داده شده اند که InfluxDB از معروفترین آنهاست اما وجود یک دیتابیس رابطهای کارآمد در این حوزه، به شدت احساس میشد. این نیاز باعث پاگرفتن پایگاه داده TimeScaleDb به عنوان یک افزونه بر روی پایگاه داده PostGreSQL شد.

دادههای سری زمانی
دادههای سری زمانی دادههایی هستند که هر رکورد آنها شامل زمان بوده، تحلیل و پردازش آنها به طور معمول وابسته به بازههای زمانی است. از جمله این نوع دادهها میتوان به دادههای بورس، آبوهوا، توئیتها و حتی اخبار اشاره کرد.
سریهای زمانی در تمامی حوزههای علوم کاربردی و مهندسی که زمان در آنها اندازهگیری و ذخیره میشود از سالیان دور حضور داشتهاند. بنابراین، مکانیسم های ماندگاری دادهها برای سریهای زمانی از جمله کارهای قدیمی برای پایگاه دادهها هستند. بانکهای اطلاعاتی سری زمانی(TSDB)، نوع خاصی از پایگاههای داده هستند که برای ذخیره و پردازش بهینه دادههای سریزمانی (زمانمحور) ایجاد شدهاند.
تعریف ریاضی سری زمانی (Time Series)
دنبالهای از دادهها که در یک محدود زمانی جمعآوری شدهاند، یک سری زمانی را تشکیل میدهند. این دادهها تغییراتی که پدیده در طول زمان دچار شده را منعکس میکنند. بنابراین میتوانیم این مقدارها را یک بردار وابسته به زمان بدانیم. در این حالت اگر X یک بردار باشد، سری زمانی را میتوان به صورت زیر نشان داد؛ که در آن t، بیانگر زمان و X نیز یک متغیر تصادفی است.
طبق این تعریف زمان t=0 نیز قابل تعریف است. این لحظه میتواند زمان تولد یک پدیده یا هنگامی باشد که اولین اطلاعات در آن لحظه ثبت شده است. به این ترتیب
متغیر تصادفی X را در زمان t نشان میدهد. مقدارهای مشاهده شده این متغیر تصادفی دارای ترتیبی هستند که زمان وقوع هر داده را نشان میدهند.
اگر متغیر تصادفی X، یک بعدی باشد، یعنی از بین ویژگیهای مختلف یک پدیده فقط از یکی ویژگی برای ایجاد مدل سری زمانی استفاده شود، مدل را «یک متغیره» (Univariate) مینامند. ولی اگر از چندین ویژگی برای ایجاد مدل سری زمانی استفاده شود، مدل سری زمانی را «چند متغیره» (Multivariate) میگویند. البته اگر علاوه بر زمان، مکان یا مختصات را (یا هر اطلاعاتی که مقدار دادهها به آن وابسته باشند) به مدل اضافه کنیم، وارد مبحث «آمار فضایی» (Spatial Statistic) خواهیم شد.
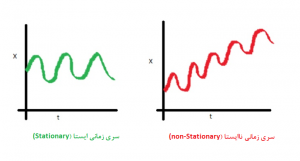
داده های سری زمانی متفاوت هستند!
مشکل اصلی در رابطه با پایگاه داده های سری زمانی از جایی شروع شد که شرکت IBMدر سال ۱۹۷۰، Seminal System R را راه انداخت و از پایگاه داده های رابطه ای برای پردازش تراکنش های آنلاین (OLTP) استفاده شد.
در OLTP عملیات عمدتا از جنس تراکنش های آپدیت بود که سطرهای مختلفی از پایگاه داده را تغییر می داد. برای مثال به یک ترانش انتقال وجه بانک توجه کنید که در آن پولی از یک حساب برداشت شده و به حساب شخص دیگری واریز می شود. در این انتقال، دو سطر و احتمالاً دو فیلد از هر سطر، آپدیت میشود.
در داده های سری زمانی ، با جریان پیوستهای از دادهها و یا اندازهگیریها (در مورد حسگرها) مواجه هستیم که در همه آنها، عملیات اصلی مورد نیاز، اضافه کردن “اطلاعات جدید” به پایگاهداده به صورت پیوسته است.
البته این امکان وجود دارد که اطلاعات بسیار دیرتر از زمانی برسد که تولید شده یا برچسب زمانی خورده و یا به علت تاخیر شبکه / سیستم یا به دلیل اصلاحات برای به روز رسانی دادههای موجود، این امر نوعاً استثنا است، نه یک قاعده ثابت. بنابراین بین نوع عملیات مورد نیاز سیستمهای تراکنش محور و سری زمانی، تفاوتهای ماهوی را شاهد هستیم.
در OLTP یا دادههای تراکنش محور :
- آپدیت در درجه اول اهمیت قرار دارد یعنی باید بتوان با سرعت و کارآیی مناسب، داده ها را اصلاح کرد.
- نوشتنها به صورت تصادفی توزیع شده هستند و نمیتوان پیشبینی کرد نوشتن بعدی، قرار است بر روی کدام داده انجام شود.
- اغلب تراکنش ها شامل چندین جدول مختلف میشوند یعنی باید چندین کلید اصلی را جستجو و دادههای آنها را بازیابی کرد.
در دادههای سری زمانی:
- Insertها در درجه اول اهمیت هستند.
- نوشتن ها تصادفی نیست و در بازه زمانی اخیر انجام می شود. (زمانمند هستند و به ترتیب زمانی وارد میشوند)
- کلید اصلی اغلب یک TimeStampاست و ممکن است علاوه بر TimeStampموارد دیگری نیز چون ServerID، ِDeviceID و … همراه با TimeStampباشد.
راه حل پایگاه دادههای رابطهای برای پردازش سری زمانی در پایگاه داده TimescaleDB
در شکل زیر راه حل استاندارد اولیه پایگاه داده های رابطه ای برای پردازش جریان داده ای و ایده نوین اَبَرجدول در TimescaleDBدیده می شود. در راه حل اولیه که همان استفاده از ایندکسهای B+است، بخشی از نودهای میانی، در حافظه نگهداری میشوند تا فرآیند جستجو و بازیابی اطلاعات سرعت مناسب داشته باشد اما در رهیافت جدید TimescaleDB، دادهها به بخشها یا Chunkهایی تقسیم و ذخیره میشوند و همواره آخرین بخشها در حافظه نگهداری میشود. کاربران از طریق اَبَرجدولها به این بخشها دسترسی خواهند داشت.
به عبارت دقیقتر، در پایگاه داده TimescaleDBکه قصد دارد از پایگاهداده رابطهای پستگرس برای ذخیره دادههای سری زمانی به نحو موثر استفاده کند، از مفهوم Hyper table و Chunk استفاده می شود. یک جدول مجازی یا اَبَرجدول، در واقع یک تجرید یا یک دید مجازی از همه جداول منفردی است که داده ها را در خود جای داده اند. این جداول منفرد تشکیل دهنده یک اَبَرجدول، chunk نامیده می شوند.
هر Chunkدر یک جدول پایگاه داده داخلی (به عنوان یک جدول معمولی) ذخیره میشود، بنابراین ایندکس ها فقط با اندازه هر Chunkرشد می کنند و نه به اندازه کل. در HyperTableاز آنجا که دادهها معمولاً در یک بازه محدود (چند ثانیه قبل یا بعد از زمان جاری سیستم بسته به تاخیر یا عدم تنظیم بودن ساعت دستگاهها) وارد میشوند، میتوان همواره آخرین Chunkرا در حافظه نگه داشت. با اینکار از یک Swap پرهزینه به دیسک جلوگیری می شود.

مزایای Chunking
از آنجا که هریک از این chunk ها به صورت جدولهایی در پایگاه داده ذخیره می شوند، و Query Plannerاز محدوده chunkها آگاه است (اندیس زمان و مکان)، Query Planner می تواند به سرعت تعیین کند که کدام داده عملیاتی متعلق به کدام chunk است. این موضوع می تواند هم برای درج سطرها، وهم برای انتخاب مجموعه ای از chunkها که برای اجرای کوئری مورد نیاز است، استفاده شود.
داده کاوی مبتنی بر سریهای زمانی
تحلیل سریهای زمانی تکنیکی در دادهکاوی که هدف از آن، یافتن خصوصیات جالب توجه و نظمهای مشخص در داده های حجیم است. یکی از سری های زمانی دنبالهای مرتب شده از مشاهدات است که،ارزش یک شیء را به عنوان تابعی از زمان در مجموعه دادههای جمع آوری شده توصیف میکند. رخداد وقایع متوالی در اصل مجموعهی وقایعی است که بعد از یک واقعهی مشخص به وقوع میپیوندند.
هدف اصلی در تحلیل سری زمانی در مورد یک پدیده، ایجاد یک مدل آماری برای دادههای وابسته به زمان براساس اطلاعات گذشته آن پدیده است. با این کار امکان پیشبینی در مورد آینده پدیده مورد بحث میسر میشود. به بیان دیگر تحلیل سری زمانی، ایجاد مدلی گذشتهنگر است تا امکان تصمیمات آیندهنگر را فراهم سازد.
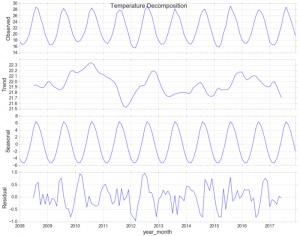
مولفههای یک سری زمانی
معمولا میتوان الگوی رفتار یا مدل تغییرات یک سری زمانی را به چهار مولفه تفکیک کرد. «روند» (Trend)، «تناوب» (Cyclic)، «فصل» (Seasonal) و «تغییرات نامعمول» (Irregular). اگر نمودار مربوط به دادههای سری زمانی را برحسب زمان ترسیم کنیم میتوانیم این مولفهها را تشخیص دهیم در نتیجه شناخت بهتری از دادههای سری زمانی خواهیم داشت. در ادامه به معرفی و بررسی هر یک از این مولفهها میپردازیم.

- روند (Trend): تمایل سری زمانی به افزایش، کاهش یا حتی ثابت بودن، روند را تشکیل میدهد. در یک سری زمانی با روند افزایشی، انتظار داریم مقدارهای سری زمانی در زمانهای
و به صورت
- باشند. برای مثال روند برای سری زمانی مربوط به میزان جمعیت یا سرمایه در بازار بورس به صورت افزایشی، ولی روند برای میزان مرگ و میر با توجه به پیشرفت در امور پزشکی، کاهشی است.
تناوب (Cyclic): تغییرات یکسان و تکراری در مقاطع میانمدت، تناوب در سری زمانی نامیده میشود. معمولا این تناوب ممکن است هر دو سال یا بیشتر اتفاق بیافتد. برای مثال تناوب در کسب و کار دارای یک چرخه چهار مرحلهای است که باعث میشود دادههای مربوط به کسب و کار در یک دوره تناوب 3 ساله تکرار شوند.
فصل (Seasonal): در سری زمانی، تغییراتی که در دورهای کوتاهتر از یک تناوب به صورت تکراری رخ میدهد، به تغییرات فصلی معروف است. برای مثال در طول یک سال میزان فروش لباسهای گرم در زمستان افزایش داشته و سپس در فصلهای دیگر کاهش داشته است. این تناوب در سالهای بعد نیز به همین شکل تکرار میشود. همانطور که مشخص است دوره تکرار تغییرات فصلی کوتاهتر از دوره تکرار برای تغییرات تناوبی است.
تغییرات نامعمول (ّIrregular): این گونه تغییرات بر اثر عوامل تصادفی و غیرقابل پیشبینی ایجاد میشوند. برای مثال زلزله یا سیل در بررسی رشد جمعیت ممکن است اثرات بزرگی داشته باشد. این مولفه بعد از شناسایی توسط نمودار ترسیم شده از سری زمانی باید حذف شود. در غیر اینصورت نتایج حاصل از تحلیل سری زمانی ممکن است گمراه کننده باشند.
منابع:
https://blog.timescale.com/blog/time-series-data-why-and-how-to-use-a-relational-database-instead-of-nosql-d0cd6975e87c/
https://www.bigdata.ir/1399/01/timescaledb-%d9%85%d9%86%d8%a7%d8%b3%d8%a8-%d8%a8%d8%b1%d8%a7%db%8c-%d8%af%d8%a7%d8%af%d9%87%e2%80%8c%d9%87%d8%a7%db%8c-%d8%b3%d8%b1%db%8c-%d8%b2%d9%85%d8%a7%d9%86%db%8c/.
.https://blog.faradars.org/time-series/
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 3236
برچسبTimescaleDB الگوریتم سریهای زمانی انواع تحلیل های سری زمانی پایگاه داده TimescaleDB داده کاوی سریهای زمانی داده کاوی مبتنی بر سریهای زمانی داده های حجیم دادههای سری زمانی سري زماني سری های زمانی مزایای Chunking
نوشته های مرتبط












همچنین ببینید
نسل جدید دیسک های ذخیره سازی نوری برای داده های طولانی
مقدمه بر نسل جدید دیسک ها: دانشمندان استرالیا و چین از نانومواد طلا برای ساخت …
فیلم آموزش آپاچی اسپارک به زبان ساده از شرکت لیندا
معرفی آپاچی اسپارک در پست های قبلی با معماری آپاچی اسپارک آشنا شدیم. اسپارک یک …
