خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
تفاوت کدهای اسکی با Unicode
یکی از اولین مراحل در پردازش متن آشنایی با کدگذاری های حروف است. در این مبحث به برسی کد اسکی میپردازیم. «انجمن ملی استاندارد آمریکا» (America National Standard Association, ANSI) در ۶ اکتبر 1۹۶۰ شروع به کار بر روی «کدهای اسکی» (ASCII) کرد. طرح اولیه این کدگذاری به صورت ۵ بیتی در کدهای تلگرافی داشت و توسط «امیلی بادوت» (Emile baudot) ابداع شد. اما در پایان کمیته طراح تصمیم به استفاده از کد ۷ بیتی گرفت.
عناوين مطالب: '
مقدمه بر کدهای اسکی
در این روش رمزگذاری HELLO اعداد ۷۲, ۶۹, ۷۶, ۷۶, ۷۹ است و به صورت دیجیتالی بدین گونه ۱۰۰۱۰۰۰ ۱۰۰۰۱۰۱ ۱۰۰۱۱۰۰ ۱۰۰۱۱۰۰ ۱۰۰۱۱۱۱ منتقل میشوند. (یک روش خیلی ساده برای تبدیل اعداد از مبنای ۱۰ به مبنای ۲ استفاده از ماشین حساب ویندوز است. ماشین حساب ویندوز را اجرا کرده و منوی View گزینه Scientific را علامت بزنید تا گزینههایی به ماشین حساب اضافه شود. حال عدد مورد نظر خود در مبنای ۱۰ را وارد کنید و گزینه Bin را که به معنای باینری است انتخاب کنید، عدد به صورت باینری به نمایش درمیآید.)
با استفاده از ۷ بیت، ۱۲۸ مقدار ممکن از ۰۰۰۰۰۰۰ تا ۱۱۱۱۱۱۱ خواهد بود بنابراین ASCII دارای فضای کافی برای همه حروف کوچک و بزرگ لاتین همراه با همه رقمها، علائم نقطه گذاری مشترک، فاصلهها (spaces)، تبها (tabs) و کاراکترهای کنترلی دیگر است. در سال ۱۹۶۸ Lyndon B. Johnson رییس جمهور ایلات متحده آن را رسمی کرد – تمام کامپیوترها باید ASCII را استفاده و درک کنند.
کدهای اسکی در کامپیوترها، وسایل ارتباطی و هر وسیله دیگری که با متن سروکار دارد، برای نمایش متون استفاده میشوند. تمام مجموعه کارکترهای نسل جدید (مانند یونیکد و UTF) از اسکی نشأت میگیرند. هر کاراکتر اسکی دارای یک کد عددی معادل است. اسکی اولین بار در سال ۱۹۶۷ ابداع گردید و آخرین بار در سال ۱۹۸۶ دچار تغییر شد. در حال حاضر ۳۳ کاراکتر آن غیرقابل چاپ میباشند، که اکثر آنها کاراکترهای کنترلی هستند که روی ظاهر متن تأثیر دارند. ۹۵ کارکتر اسکی قابل چاپ هستند که آنها را در اینجا میبینید:
!"#$%&'()*+,-./0123456789:;<=>?
@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_
`abcdefghijklmnopqrstuvwxyz{|}~
کدهای اسکی نوع توسعه یافتهٔ این سیستم کد گذاری
کدهای اسکی نوع توسعه یافتهٔ این سیستم کد گذاری، ۸ رقمی بوده و قادر است ۲۵۶ کاراکتر را کدگذاری کند. برای نمونه کد حرف “W” عدد ۸۷ میباشد، شما میتوانید در یک ویرایشگر متنی در حالی که دکمهٔ Alt را فشار دادهاید عدد ۸۷ را وارد نمایید تا با رها کردن Alt حرف “W” را مشاهده نمایید. از این سیستم در PCها استفاده میشود.
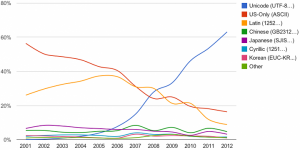
یونیکد برای نجات
در اواخر ۱۹۸۰ یک استاندارد جدید پیشنهاد شد که یک شماره منحصر به فرد (که به طور رسمی به عنوان code point شناخته میشد) را به هر حرف در هر زبان اختصاص میداد. در این روش بیشتر از ۲۵۶ مقدار مورد نیاز بود. این روش Unicode (یونیکد) نامیده شد. ورژن یونیکد هم اکنون ۶٫۱ و شامل بیش ۱۱۰۰۰۰ کد پوینت است. در صورت تمایل میتوانید همه آنها را مشاهده کنید.
کد پوینت ابتدایی یونیکد همانند اَسکی هستند. محدوده ۱۲۸ تا ۲۵۵ شامل نمادهای ارز و سایر نمادهای معمول و کاراکترهای استرسدار (به عنوان کاراکترهای با علائم تشخیصی برای تلفظ [diacritical marks] شناخته میشوند) هستند، و بیشتر آن از ISO-8859-1 گرفته شدهاند. بعد از ۲۵۶، کاراکترهای استرسدار بسیار بیشتری قرار دارند. پس از ۸۸۰ به حروف یونانی میرسد، سپس سیریلیک، عبری، عربی، هندی و تایلندی. چینی، ژاپنی و کرهای از ۱۱۹۰۴ آغاز میشوند و بسیاری دیگر در این بین قرار دارند.
این مهم است که هر حرف به وسیله شماره منحصر به فرد خود نمایش داده میشود. حرف Я سیریلیکی همیشه ۱۰۷۱ و حرف α یونانی همیشه ۹۴۵ است. à همیشه ۲۲۴ و H 72 است. توجه داشته باشید که این کد پوینتهای یونیکد به طور رسمی به صورت هگزادسیمال با U+ در ابتدای آنها نوشته میشوند. بنابراین کد پوینت یونیکد H به جای ۷۲ معمولاً به صورت U+0048 نوشته میشود ( برای تبدیل هگزادسیمال [مبنای شانزده] به دسیمال [مبنای ده] : ۷۲ = ۴ * ۱۶ + ۸).
مشکل اصلی این است که بیشتر از ۲۵۶ تا از آنها وجود دارد. کاراکترهای بعد از ۲۵۶ در ۸ بیت جا نخواهند شد. هر چند یونیکد، مجموعه کاراکتری یا کد پیج نیست. بنابراین این مشکل کنسرسیوم یونیکد نیست. آنها فقط ایده را مطرح کردند و اجازه دادند تا هر کسی پیاده سازی خود را انجام دهد.
یونیکد در داخل مرورگر
یونیکد در داخل ۸ بیت یا حتی ۱۶ بیت جا نمیشود. اگرچه تنها ۱۱۰۱۱۶ کد پوینت استفاده شده، قابلیت آن را دارد تا ۱۱۱۴۱۱۲ از آنها تعریف شود که ۲۱ بیت نیاز دارد. به هرحال کامپیوترها از سال ۱۹۷۰ پیشرفت کرده بودند و یک ریزپردازنده ۸ بیتی قدیمی شده بود. کامپیوترهای جدید اکنون پردازندههای ۶۴ بیتی دارند بنابراین چرا ما نتوانیم از یک کاراکتر ۸ بیتی به سمت یک کاراکتر ۳۲ یا ۶۴ بیت برویم؟
نخستین جواب این است : ما میتوانیم!
نرمافزارهای زیادی که با C یا ++C نوشته شدهاند از کاراکتر عریض (wide character) پشتیبانی میکنند. این یک کاراکتر ۳۲ بیتی است که wchar_t نامیده شده است. این یک بسطی از گونه char، ۸ بیتی C است. مرورگرهای وب مدرن از کاراکترهای عریض (یا چیزی شبیه به آن) به صورت داخلی استفاده میکنند و از لحاظ تئوری میتوانند با ۴ بیلیون کاراکتر متمایز سروکار داشته باشند. این مقدار برای یونیکد کفایت میکند بنابراین مرورگرهای وب مدرن به صورت داخلی از یونیکد استفاده میکنند.
UTF-8 برای نجات
اگر مرورگرها میتوانند با کاراکترهای ۳۲ بیتی یونیکد کار کنند پس مشکل کجاست؟ مشکل در ارسال و دریافت و خواندن و نوشتن کاراکترهاست.
مشکل باقیست چون:
- بسیاری از نرمافزارها و پروتکلهای ارسال/دریافت و خواندن/نوشتن با کاراکترهای ۸ بیتی کار میکنند
- با استفاده از ۳۲ بیت برای ارسال/ذخیره متن انگلیسی مقدار پهنای باند/فضای موردنیاز چهار برابر خواهد شد
هر چند مرورگرها میتوانند بصورت داخلی با یونیکد کار کنند، هنوز باید برای مرورگر وب داده را از وب سرور بگیرید و دوباره برگردانید، و نیاز دارید تا آن را در یک فایل یا جایی در یک پایگاه داده ذخیره کنید. بنابراین هنوز به راهی نیاز دارید که ۱۱۰۰۰۰ کد پوینت یونیکد را تنها در ۸ بیت جا دهید.
تلاشهای مختلفی برای حل این مسأله انجام گرفته مثل UCS2 و UTF-16. اما در سالهای اخیر UTF-8 برنده بوده است که مخفف فرمت ۸ بیتی انتقال مجموعه کاراکتری جهانی (Universal Character Set Transformation Format 8 bit) است.
UTF-8 باهوش است و نسبتاً شبیه کلید Shift روی کیبورد کار میکند. به طور معمول هنگامی که شما H را از کیبورد میفشارید حرف کوچک h روی صفحه ظاهر میشود. اما اگر شما ابتدا Shift را فشار داده باشید، حرف بزرگ H ظاهر میشود.
UTF-8 با اعداد ۰ تا ۱۲۷ همانند اَسکی، ۱۹۲ تا ۲۴۷ به عنوان کلیدهای Shift و ۱۲۸ تا ۱۹۲ به عنوان کلیدهایی که با شیفت استفاده میشوند، رفتار میکند. برای مثال کاراکترهای ۲۰۸ و ۲۰۹ شما را به محدوده سیریلیک منتقل میکنند (شیفت میدهند). ۲۰۸ همراه با ۱۷۵ کاراکتر ۱۰۷۱ است که Я سیریلیک میشود. محاسبه دقیق آن به این صورت است: ۱۰۷۱ = (۶۴ % ۱۷۵) + ۶۴ * (۳۲ % ۲۰۸). کاراکترهای ۲۲۴ تا ۲۳۹ شبیه شیفت مضاعف (double shift) هستند. ۲۲۶ به دنبال آن ۱۹۰ و سپس ۱۲۸ کاراکتر ۱۲۱۶۰: ⾀ است. ۲۴۰ به بالا شیفت سه گانه (triple shift) است.
بنابراین UTF-8 یک رمزگذاری با عرض متغیر (variable-width) چند بایتی (multi-byte) است. چند بایتی به خاطر اینکه یک کاراکتر واحد شبیه Я بیشتر از یک بایت را برای مشخص شدن میگیرد. عرض متغیر به این دلیل که برخی از کاراکترها مثل H تنها یک بایت را میگیرند و برخی تا چهار بایت را اشغال میکنند.
بهتر از همه این است که با ASCII نیز سازگار است. بر خلاف برخی دیگر از راه حلهای پیشنهادی، هر سندی که تنها در ASCII با کاراکترهای ۰ تا ۱۲۷ نوشته شده کاملاً در UTF-8 معتبر است و همچنین موجب صرفه جویی در پهنای باند میشود.
جدول کدهای اسکی
|
علامت |
نام علامت |
شماره علامت |
|
“ |
" |
" |
|
& |
& |
& |
|
< |
< |
< |
|
> |
> |
> |
|
|
|
  |
|
¡ |
¡ |
¡ |
|
¤ |
¤ |
¤ |
|
¢ |
¢ |
¢ |
|
€ |
€ |
€ |
|
£ |
£ |
£ |
|
¥ |
¥ |
¥ |
|
¦ |
¦ |
¦ |
|
§ |
§ |
§ |
|
¨ |
¨ |
¨ |
|
© |
© |
© |
|
ª |
ª |
ª |
|
« |
« |
« |
|
¬ |
¬ |
¬ |
|
|
­ |
­ |
|
® |
® |
® |
|
™ |
™ |
|
|
¯ |
¯ |
¯ |
|
° |
° |
° |
|
± |
± |
± |
|
² |
² |
² |
|
³ |
³ |
³ |
|
´ |
´ |
´ |
|
µ |
µ |
µ |
|
¶ |
¶ |
¶ |
|
· |
· |
· |
|
¸ |
¸ |
¸ |
|
¹ |
¹ |
¹ |
|
º |
º |
º |
|
» |
» |
» |
|
¼ |
¼ |
¼ |
|
½ |
½ |
½ |
|
¾ |
¾ |
¾ |
|
¿ |
¿ |
¿ |
|
× |
× |
× |
|
÷ |
÷ |
÷ |
|
À |
À |
À |
|
Á |
Á |
Á |
|
 |
 |
 |
|
à |
à |
à |
|
Ä |
Ä |
Ä |
|
Å |
Å |
Å |
|
Æ |
Æ |
Æ |
|
Ç |
Ç |
Ç |
|
È |
È |
È |
|
É |
É |
É |
|
Ê |
Ê |
Ê |
|
Ë |
Ë |
Ë |
|
Ì |
Ì |
Ì |
|
Í |
Í |
Í |
|
Î |
Î |
Î |
|
Ï |
Ï |
Ï |
|
Ð |
Ð |
Ð |
|
Ñ |
Ñ |
Ñ |
|
Ò |
Ò |
Ò |
|
Ó |
Ó |
Ó |
|
Ô |
Ô |
Ô |
|
Õ |
Õ |
Õ |
|
Ö |
Ö |
Ö |
|
Ø |
Ø |
Ø |
|
Ù |
Ù |
Ù |
|
Ú |
Ú |
Ú |
|
Û |
Û |
Û |
|
Ü |
Ü |
Ü |
|
Ý |
Ý |
Ý |
|
Þ |
Þ |
Þ |
|
ß |
ß |
ß |
|
à |
à |
à |
|
á |
á |
á |
|
â |
â |
â |
|
ã |
ã |
ã |
|
ä |
ä |
ä |
|
å |
å |
å |
|
æ |
æ |
æ |
|
ç |
ç |
ç |
|
è |
è |
è |
|
é |
é |
é |
|
ê |
ê |
ê |
|
ë |
ë |
ë |
|
ì |
ì |
ì |
|
í |
í |
í |
|
î |
î |
î |
|
ï |
ï |
ï |
|
ð |
ð |
ð |
|
ñ |
ñ |
ñ |
|
ò |
ò |
ò |
|
ó |
ó |
ó |
|
ô |
ô |
ô |
|
õ |
õ |
õ |
|
ö |
ö |
ö |
|
ø |
ø |
ø |
|
ù |
ù |
ù |
|
ú |
ú |
ú |
|
û |
û |
û |
|
ü |
ü |
ü |
|
ý |
ý |
ý |
|
þ |
þ |
þ |
|
ÿ |
ÿ |
ÿ |
|
Π|
Π|
Π|
|
œ |
œ |
œ |
|
Š |
Š |
Š |
|
š |
š |
š |
|
Ÿ |
Ÿ |
Ÿ |
|
ˆ |
ˆ |
ˆ |
|
˜ |
˜ |
˜ |
|
Α |
Α |
Α |
|
Β |
Β |
Β |
|
Γ |
Γ |
Γ |
|
Δ |
Δ |
Δ |
|
E |
Ε |
Ε |
|
Z |
Ζ |
Ζ |
|
H |
Η |
Η |
|
Θ |
Θ |
Θ |
|
I |
Ι |
Ι |
|
K |
Κ |
Κ |
|
Λ |
Λ |
Λ |
|
M |
Μ |
Μ |
|
N |
Ν |
Ν |
|
Ξ |
Ξ |
Ξ |
|
O |
Ο |
Ο |
|
Π |
Π |
Π |
|
P |
Ρ |
Ρ |
|
Σ |
Σ |
Σ |
|
T |
Τ |
Τ |
|
Y |
Υ |
Υ |
|
Φ |
Φ |
Φ |
|
X |
Χ |
Χ |
|
Ψ |
Ψ |
Ψ |
|
Ω |
Ω |
Ω |
|
α |
α |
α |
|
β |
β |
β |
|
γ |
γ |
γ |
|
δ |
δ |
δ |
|
ε |
ε |
ε |
|
ζ |
ζ |
ζ |
|
η |
η |
η |
|
θ |
θ |
θ |
|
ι |
ι |
ι |
|
κ |
κ |
κ |
|
λ |
λ |
λ |
|
μ |
μ |
μ |
|
ν |
ν |
ν |
|
ξ |
ξ |
ξ |
|
ο |
ο |
ο |
|
π |
π |
π |
|
ρ |
ρ |
ρ |
|
ς |
ς |
ς |
|
σ |
σ |
σ |
|
τ |
τ |
τ |
|
υ |
υ |
υ |
|
φ |
φ |
φ |
|
χ |
χ |
χ |
|
ψ |
ψ |
ψ |
|
ω |
ω |
ω |
|
– |
– |
– |
|
— |
— |
— |
|
‘ |
‘ |
‘ |
|
’ |
’ |
’ |
|
‚ |
‚ |
‚ |
|
“ |
“ |
“ |
|
” |
” |
” |
|
„ |
„ |
„ |
|
† |
† |
† |
|
‡ |
‡ |
‡ |
|
… |
… |
… |
|
‰ |
‰ |
‰ |
|
′ |
′ |
′ |
|
″ |
″ |
″ |
|
‹ |
‹ |
‹ |
|
› |
› |
› |
|
‾ |
‾ |
‾ |
|
⁄ |
⁄ |
⁄ |
|
← |
← |
← |
|
↑ |
↑ |
↑ |
|
→ |
→ |
→ |
|
↓ |
↓ |
↓ |
|
↔ |
↔ |
↔ |
|
∩ |
∩ |
∩ |
|
∞ |
∞ |
∞ |
|
∫ |
∫ |
∫ |
|
≈ |
≈ |
≈ |
|
≠ |
≠ |
≠ |
|
≡ |
≡ |
≡ |
|
≤ |
≤ |
≤ |
|
≥ |
≥ |
≥ |
|
√ |
√ |
√ |
|
∑ |
∑ |
∑ |
|
∏ |
∏ |
∏ |
|
∂ |
∂ |
∂ |
|
◊ |
◊ |
◊ |
|
♠ |
♠ |
♠ |
|
♣ |
♣ |
♣ |
|
♥ |
♥ |
♥ |
|
♦ |
♦ |
♦ |
منابع:
http://webtarget.ir/%D9%87%D9%85%D9%87-%DA%86%D9%8A%D8%B2-%D8%AF%D8%B1-%D9%85%D9%88%D8%B1%D8%AF-unicode-utf8/
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 4984
برچسبASCII Unicode UTF-8 اسکی تفاوت کدهای اسکی با Unicode جدول کدهای اسکی کد های اسکی کدهای ASCII کدهای اسکی مجموعه کدهای اسکی ینوکد یو تی اف یو تی اف 8 یونی کد