 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آشنایی با پردازش زبان طبیعی استنفورد (Stanford CoreNLP)
Stanford CoreNLP مجموعه ای از ابزارهای آنالیز زبان طبیعی را فراهم می آورد. این نرم افزار می تواند یک متن خام به زبان انگلیسی را به عنوان ورودی گرفته و شکل اولیه کلمات، بخش های گفتاری کلمات، تشخیص اسم خاص بودن کلمات، نرمال کردن تاریخ، زمان و مقادیر عددی، مشخص کردن ساختار جملات بر حسب وابستگی های کلمه و عبارات، و مشخص کردن عبارت های اسمی که به موجودیت های یکسان اشاره می کنند را به عنوان خروجی برگرداند.
قابلیت های Stanford CoreNLP:
پردازش زبان طبیعی استنفورد دارای یک چهارچوب یکپارچه می باشد و این باعث می شود که مجموعه ای از ابزارهای تحلیل زبان به راحتی بر روی متن به کار گرفته شود. پردازش زبان طبیعی استنفورد تمامی ابزار NLP مورد نیاز ما را فراهم می آورد و تنها با نوشتن دو خط کد می توان تمامی ابزار مورد نیاز را بر روی متن اجرا کرد.
Stanford CoreNLP به صورت انعطاف پذیر طراحی شده و همچنین دارای قابلیت توسعه پذیری می باشد و تنها با یک تغییر جزیی می توانیم مشخص کنیم که کدام یک از ابزارها فعال و کدامین غیرفعال شوند.
این نرم افزار به زبان جاوا نوشته شده است.
StanfordCoreNLP شامل SUTime می باشد. SUTime کتابخانه ای برای شناسایی و نرمال سازی عبارات زمانی می باشد.در بردارنده ی TokensRegex می باشد. TokensRegex یک چهارچوب برای تعریف عبارات منظم بر روی متون و توکن ها و نگاشت متون انطباق یافته به اشیاء معنادار می باشد.دارای قابلیت اضافه کردن یک حاشیه گذار جدید بدون تغییر دادن کدها در StanfordCoreNLP.java می باشد. برای ایجاد یک حاشیه گذار جدید، بایستی کد edu.stanford.nlp.pipeline.Annotator را گسترش دهیم.دارای یکد UIMA wrapper به نام Cleartk-stanford-corenlp می باشد.در Stanford CoreNLP امکان پردازش کردن لیستی از فایل ها نیز وجود دارد.
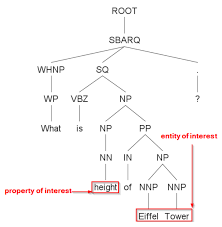
معمولاْ قبل از استفاده از CoreNLP یک فایل پیکربندی(فایل ویژگی های جاوا) ایجاد می شود. این فایل باید شامل ویژگی به نام annotators باشد. annotators شامل لیستی ازنام ابزارهای مورد استفاده می باشد که بوسیله ی “کاما” از یکدیگر جدا شده اند. به عنوان مثال تنظیمات زیر
annotators = tokenize, ssplit, pos, lemma, ner, parse, dcoref.
عملیات توکن کردن، جداسازی عبارات، برچسب زنی کلمات، ریشه يآبی کلمات، شناسایی موجودیت ها، تجزیه نحوی ، و شناسایی مراجع ضمایر را مشخص می کند.برای هر فایل ورودی، Stanford CoreNLP یک فایل خروجی XML تولید می کند. لازم به ذکر است که خروجی XML از یک فایل stylesheet به نامCoreNLP-to-HTML.xsl استفاده می کند و این stylesheet باعث می شود که یک خروجی خوانا از محتویاتXML ایجاد شود. به عنوان مثال در صورتی که ورودی
Stanford University is located in California. It is a great university.
به Stanford CoreNLP داده شود، خروجی زیر تولید می شود:
Sentences
Sentence #1
Tokens
|
Id |
Word |
Lemma |
Char begin |
Char end |
POS |
NER |
Normalized NER |
|
1 |
Stanford |
Stanford |
0 |
8 |
NNP |
ORGANIZATION |
|
|
2 |
University |
University |
9 |
19 |
NNP |
ORGANIZATION |
|
|
3 |
is |
be |
20 |
22 |
VBZ |
O |
|
|
4 |
located |
locate |
23 |
30 |
VBN |
O |
|
|
5 |
in |
in |
31 |
33 |
IN |
O |
|
|
6 |
California |
California |
34 |
44 |
NNP |
LOCATION |
|
|
7 |
. |
. |
44 |
45 |
. |
O |
Parse tree
(ROOT (S (NP (NNP Stanford) (NNP University)) (VP (VBZ is) (VP (VBN located) (PP (IN in) (NP (NNP California))))) (. .)))
Uncollapsed dependencies
- nn ( University-2 , Stanford-1 )
- nsubjpass ( located-4 , University-2 )
- auxpass ( located-4 , is-3 )
- prep ( located-4 , in-5 )
- pobj ( in-5 , California-6 )
Collapsed dependencies
- nn ( University-2 , Stanford-1 )
- nsubjpass ( located-4 , University-2 )
- auxpass ( located-4 , is-3 )
- prep_in ( located-4 , California-6 )
Collapsed dependencies with CC processed
- nn ( University-2 , Stanford-1 )
- nsubjpass ( located-4 , University-2 )
- auxpass ( located-4 , is-3 )
- prep_in ( located-4 , California-6 )
Sentence #2
Tokens
|
Id |
Word |
Lemma |
Char begin |
Char end |
POS |
NER |
Normalized NER |
|
1 |
It |
it |
46 |
48 |
PRP |
O |
|
|
2 |
is |
be |
49 |
51 |
VBZ |
O |
|
|
3 |
a |
a |
52 |
53 |
DT |
O |
|
|
4 |
great |
great |
54 |
59 |
JJ |
O |
|
|
5 |
university |
university |
60 |
70 |
NN |
O |
|
|
6 |
. |
. |
70 |
71 |
. |
O |
Parse tree
(ROOT (S (NP (PRP It)) (VP (VBZ is) (NP (DT a) (JJ great) (NN university))) (. .)))
Uncollapsed dependencies
- nsubj ( university-5 , It-1 )
- cop ( university-5 , is-2 )
- det ( university-5 , a-3 )
- amod ( university-5 , great-4 )
Collapsed dependencies
- nsubj ( university-5 , It-1 )
- cop ( university-5 , is-2 )
- det ( university-5 , a-3 )
- amod ( university-5 , great-4 )
Collapsed dependencies with CC processed
- nsubj ( university-5 , It-1 )
- cop ( university-5 , is-2 )
- det ( university-5 , a-3 )
- amod ( university-5 , great-4 )
Coreference resolution graph
-
- sentence 2, headword 5 (gov)
- sentence 2, headword 1
ساختار CoreNLP API:
ساختار اصلی پکیج Stanford CoreNLP توسط ۲ کلاس Annotator و Annotation شکل گرفته است. Annotations ساختمان داده ای هستند که نتایج حاشیه گذاری بر روی متن را نگه می دارند و معمولا Map هستند. Annotators بیشتر شبیه به توابع هستند با این تفاوت که به جای عمل کردن بر روی اشیاء، بر روی Annotation عمل می کنند و عملیاتی نظیر tokenizing, parsing و یا NER tagging و غیره را انجام می دهند. Annotators و Annotation از طریق AnnotationPipelines با یکدیگر ارتباط برقرار می کنند. AnnotationPipelines پایپ لاینی است که دنباله ای از Annotators را ایجاد می کند.
Stanford CoreNLP به صورت یک پایپ لاین عمل می کند و از کلاس AnnotationPipelines ارث می برد و با استفاده از ابزار حاشیه گذاری بر روی متن تنظیم می شود. در ادامه به شرح Annotators و Annotations تولید شده توسط Annotators می پردازیم.
۱. اسم ویژگی:tokenize
۲. اسم کلاس Annotator:
PTBTokenizerAnnotator
3. Annotation تولید شده:
توکن های تولید شده با نوع داده ای TokensAnnotation .
فاصله کاراکتر آغازین هر توکن از ابتدای متن با نوع داده ای CharacterOffsetBeginAnnotation .
فاصله کاراکتر انتهایی هر توکن از ابتدای متن با نوع داده ای CharacterOffsetEndAnnotation .
4. توضیحات:
توکن کردن متن. همچنین tokenizer فاصله ی کاراکترآغازی و پایانی هر token از فایل ورودی را از ابتدای متن ذخیره می کند.
1. اسم ویژگی: cleanxml
2. اسم کلاس: CleanXmlAnnotator
3. Annotation تولید شده:
پس از حذف تگ های Xml خروجی با نوع داده ای XmlContextAnnotation بدست می آید.
4. توضیحات:
پاک کردن تگ های Xml از فایل ورودی.
1. اسم ویژگی: ssplit
2. اسم کلاس: WordToSentenceAnnotator
3. Annotation تولید شده:
پس از تشخیص جملات (منظور مجموعه ای از کلمات پشت سر هم می باشد)، خروجی با نوع داده ی SentencesAnnotation ذخیره می شود.
4. توضیحات:
رشته ای از tokens را به صورت عبارت جدا می کند.
1. اسم ویژگی: pos
2. اسم کلاس: POSTaggerAnnotator
3. Annotation تولید شده:
نقش گفتاری تشخیص داده شده برای هر توکن با نوع داده ای PartOfSpeechAnnotation ذخیره می شود.
4. توضیحات:
برچسب گذاری tokens با توجه به نقش گفتاری آن ها در جمله.
1. اسم ویژگی: lemma
2. اسم کلاس: MorphaAnnotator
3. Annotation تولید شده:
ریشه ی تولید شده برای هر کلمه با نوع داده ای LemmaAnnotation .
4. توضیحات:
تولید ریشه ی کلمات برای تمامی توکن های موجود در متن.
1. اسم ویژگی: ner
2. اسم کلاس: NERClassifierCombiner
3. Annotation تولید شده:
موجودیت های تشخیص داده شده با نوع داده ای NamedEntityTagAnnotation و NormalizedNamedEntityTagAnnotationذخیره می شوند.
4. توضیحات:
موجودیت های خاص(اشخاص، سازمان ها، مکان ها، چیزهای نامربوط) و موجودیت های عددی (تاریخ، زمان، پول، عدد) شناسایی می شوند. موجودیت های خاص با استفاده از ترکیب سهCRF مخصوص برچسب گذاری جملات، و آموزش دیده در بسترهای متنوع، مثل ACE و MUC شناخته می شوند. موجودیت های عددی بوسیله ی سیستم مبتنی بر قانون شناخته می شوند. موجودیت های عددی مانند تاریخ که نیازمند نرمال سازی هستند، در NormalizedNamedEntityTagAnnotation نرمال سازی می شوند.
1. اسم ویژگی: regexner
2. اسم کلاس: RegexNERAnnotator
3. Annotation تولید شده:
موجودیت های تشخیص داده شده با نوع داده ای NamedEntityTagAnnotation ذخیره می شوند.
4. توضیحات:
یک NER ساده و مبتنی بر قانون را بر روی رشته های توکنی ، با استفاده از عبارات منظم جاوا پیاده سازی می کند. هدف از این Annatator فراهم آوردن یک چهارچوب ساده برای لحاظ کردن برچسب های NE است که در بسترهای NL قدیمی حاشیه نویسی نشده اند.
1. اسم ویژگی: truecase
2. اسم کلاس: TrueCaseAnnotator
3. Annotation تولید شده:
TrueCaseAnnotation
TrueCaseTextAnnotation
4. توضیحات:
حالت درست توکن ها را در جایی از متن، که این حالت از بین رفته است را شناسایی می کند. مثل حروف بزرگ متن. این شناسایی با استفاده از مدل برچسب رشته ای CRF پیاده سازی می شود. برچسب حالت درست، به عنوان مثال INIT_UPPER در TrueCaseAnnotation ذخیره می شود. توکن تغییریافته برای انطباق با حالت درست، به عنوان TrueCaseTextAnnotation ذخیره می شود.
1. اسم ویژگی: parse
2. اسم کلاس: ParserAnnotator
3. Annotation تولید شده:
TreeAnnotation,
BasicDependenciesAnnotation,
CollapsedDependenciesAnnotation, CollapsedCCProcessedDependenciesAnnotation
TrueCaseTextAnnotation
4. توضیحات:
فراهم آوردن یک آنالیز نحوی کامل با ارائه دادن اجزاء سازنده و وابستگی ها . خروجی مبتنی بر اجزاء سازنده در TreeAnnotation ذخیره می شود. خروجی مبتنی بر وابستگی که ۳ مدل می باشند، به گونه ای که در ادامه شرح داده می شود تولید می شوند:
وابستگی های basic و uncollapsed در BasicDependenciesAnnotationذخیره می شوند.
وابستگی های collapsed درCollapsedDependenciesAnnotation ذخیره می شوند.
وابستگی های collapsed با هماهنگی های پردازش شده درCollapsedCCProcessedDependenciesAnnotation ذخیره می شوند.
1. اسم ویژگی: dcoref
2. اسم کلاس: DeterministicCorefAnnotator
3. Annotation تولید شده:
CorefChainAnnotation,
4. توضیحات:
مرجع ضمایر موجود در متن شناسایی می شوند.. گراف مرجع ضمایر در قسمت CorefChainAnnotation ذخیره می شود.
نحوه ی عملکرد Stanford CoreNLP با استفاده از یک مثال:
در قطعه کد زیر نحوه ی ایجاد کردن و استفاده از Stanford CoreNLP به عنوان یک پایپ لاین برای نمونه نشان داده شده است:
//در ابتد یک شی از نوع Properties ساخته شده و عملیات حاشیه گذاری مورد نظر به آن شیء اضافه می شوند.
Properties props = new Properties();
props.put(“annotators”, “tokenize, ssplit, pos, lemma, ner, parse, dcoref”);
//یک شی ء پایپ لاین از روی کلاس StanfordCoreNLP ساخته می شود و ویژگی های props به آن پاس داده می شوند.
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// متن ورودی خوانده می شود.
String text = … // Add your text here!
// یک شیء خالی ازنوع Annotation ساخته شده و متن ورودی در آن قرار می گیرد.
Annotation document = new Annotation(text);
//تمامی عملیات حاشیه گذاری که در ابتدا تعریف کردیم با استفاده از متد annotate اجراء می شوند.
pipeline.annotate(document);
// در ابتدا متن ورودی به تعدادی جمله تقسیم می شود. نوع داده ای هر کدام از این جملات CoreMap می باشد. CoreMap یک Map می باشد که از class objects ها به عنوان key استفاده می کند و مقادیر Value آن انواع داده ای سفارشی مورد استفاده ما هستند.
List<CoreMap> sentences =
document.get(SentencesAnnotation.class);
for(CoreMap sentence: sentences) {
//بررسی تمامی کلمات موجود در هر جمله
// CoreLabel همان CoreMap است با این تفاوت که دارای متدهای ویژ ه ای برای توکن ها می باشد.
for (CoreLabel token: sentence.get(TokensAnnotation.class)) {
//مشخص کردن توکن های متن
String word = token.get(TextAnnotation.class);
// مشخص کردن برچسبPOS توکن ها
String pos = token.get(PartOfSpeechAnnotation.class);
// مشخص کردن برچسبNER توکن ها
String ne = token.get(NamedEntityTagAnnotation.class);
}
//نمایش درخت تجزیه جمله جاری
Tree tree = sentence.get(TreeAnnotation.class);
//نمایش گراف وابستگی جمله جاری
SemanticGraph dependencies = sentence.get(CollapsedCCProcessedDependenciesAnnotation.class);
}
//نمایش گراف اتصال coreference جملات
Map<Integer, CorefChain> graph =
document.get(CorefChainAnnotation.class);
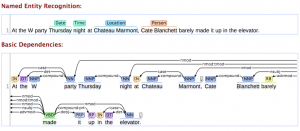
تشخیص موجودیت نام های استنفورد: Stanford Named Entity Recognizer[۱]
این ابزار، توالی نام ها (نام های خاص) از جمله اسامی سازمان ها، مکان های جغرافیایی، نام و نام خانوادگی افراد را در یک متن شناسایی و استخراج می کند، همچنین می توان این نرمافزار را جهت استخراج نام ژن ها و پروتئین ها، زمان و تاریخ نیز گسترش داد. این نرمافزار که جهت تحلیل متون و داده کاوی مورد استفاده قرار می گیرد، تحت مجوز General Public License بوده و دانلود و استفاده از آن برای همگان به صورت دسترسی آزاد امکان پذیر است، نسخه های فعلی Stanford NER نیازمند جاوا 1/8 یا بالاتر هستند.
ابزار شناساگر موجودیت نام ها، طیف گسترده ای از تکنیک های مبتنی بر یادگیری ماشین و مدل های آماری زبان را به همراه واژه نامه هایی، جهت تحلیل متون و استخراج نام ها به کار می گیرد. در اصل، ما به آن می گوییم: این یک بلوک متن طبقه بندی شده است، و این نرمافزار آن را از طریق متن پردازش می کند، به ساختار متن ما نگاه می کند و مطابق آن با مدل های آماری برای شناسایی افراد، سازمان ها و مکان ها اقدام می کند.
جهت استفاده ابتدا، NER Stanford را از http://nlp.stanford.edu/software/CRF-NER.html دانلود کنید و آن را به دستگاه خود بیفزایید. هیچ گونه روش نصب پیچیده ای برای آن وجود ندارد، شما باید قادر به اجرای Stanford NER از پوشه ای که آنرا ذخیره کرده اید، باشید. به طور معمول، Stanford NER از خط فرمان اجرا می شود.
Stanford NER نیز به عنوان CRF Classifier شناخته می شود. این نرمافزار یک پیاده سازی کلی از مدل های زنجیره خطی شرطی (CRF) را فراهم می کند، به عبارت دیگر شما می توانید از این کد برای ساخت مدل های توالی برای NER یا هر کار دیگری استفاده کنید. با وارد کردن فایل های متنی به این نرمافزار و انتخاب یکی از سه گزینه موجود در بخش CRF، نرمافزار شروع به تحلیل و پردازش داده ها می کند و درنهایت اسامی و نام ها را در متن با برجسته سازی رنگی نشان می دهد. هنگامی که برنامه پردازش را به پایان رساند، می توانیم از داده های پردازش شده جهت مصور سازی یا تحلیل های بعدی خروجی بگیریم.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 1737
برچسبNER Stanford nlp استنفورد Stanford CoreNLP استنفرد استنفورد پردازش زبان طبیعی پردازش زبان طبیعی استنفورد دوره پردازش زبان طبیعی زبان طبیعی
نوشته های مرتبط









همچنین ببینید
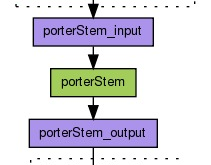
نقش ریشه یاب (Stemmer) در تحلیل متن و پردازش زبان و تفاوت آن با lemmatizer
در این مبحث مولفه ریشه یاب (Stemmer) در فرایند پردازش متن تشریح میگردند. ریشه یابی عبارت …

