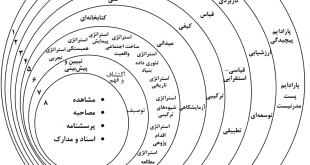
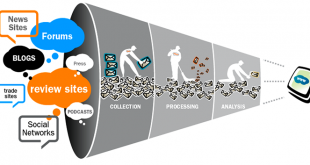
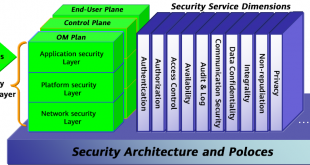
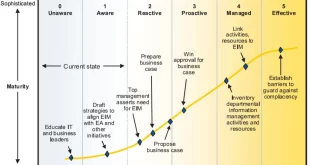
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
امروزه یکی از سرگرمیهای جذاب بشر تماشا کردن فیلم های سینمایی است. ولی انتخاب هدفمند فیلمهای سینمایی به غیر از سرگرمی می تواند نگرشهای عمیق و تخصصی تری را در رابطه با موضوعات مختلف در انسان ایجاد کند. چرا که فیلم های با زمینه …
ادامه مطلب25 فیلم سینمایی برتر با موضوع داده کاوی، هوش مصنوعی و فضای سایبر (با دوبله فارسی)