 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آموزش پایگاه داده PostgreSQL (معماری اجزاء و زیر سیستم ها )
عناوين مطالب: '
مقدمه ای بر دیتابیس PostgreSQL
پایگاه داده PostgreSQL یک سیستم پایگاه دادهی ارتباطی شیگرا و منبع باز است که برای اولینبار در سال 1997 با نام “Ingres” ایجاد شد. در اواخر دههی 1990، Postgre استانداردهای SQL را پذیرفت و نام “PostgreSQL” را اتخاذ کرد. تا به امروز، هزاران برنامهی کاربردی پایگاه داده با استفاده از PostgreSQL طراحی شده است و پذیرش گستردهی آن، تصدیقی بر اعتبار معماری مفهومی(Conceptual architecture) آن پایگاه داده از طریق تحلیل سیستماتیک است. معماری مفهومی مذکور میتواند در فرایند اعتبارسنجی مرحلهی آخر و در نتیجه ایجاد یک معماری منسجم کمک کند.
PostgreSQL از ترکیبی از سبکهای معماری استفاده میکند. در بالاترین سطح، مشتری و خدمتگزار توسط مدل مشتری-خدمتگزار کلاسیک با یکدیگر ارتباط برقرار میکنند، درحالیکه ساختار دسترسی داده کاملاً لایهبندی شده است. در لایهی خدمتگزار، پردازش پرسوجو به صورت خط لوله(Pipeline) ساختیافته، درحالیکه دسترسی به پایگاه توسط زیرسیستمهای خدمتگزار به صورت تابلو اعلانات Bulletin board() ساختیافته است. ارتباط میان مشتری و خدمتگزار تا حد زیادی مبتنی بر درخواست/پاسخ است و خدمات به هر مشتری با یک نخ(Thread) خدمتگزار جداگانه ارائه میشود. تمامی نخهای خدمتگزار به یک سیستم مدیریت دادهی مشترک دسترسی دارند.

پردازندهی پرسوجو/فرمان در پایگاه داده PostgreSQL
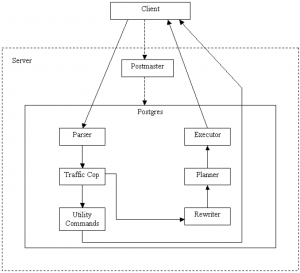
شکل زیر معماری مفهومی خدمتگزار PostgreSQL را نشان میدهد که به صورت خط لوله ساخت یافته است. این شکل جریان داده[1] و کنترل کلی در back-end را از زمانی که یک پرسوجو دریافت و تا زمانی که نتایج ارسال میشود را نشان میدهد. شش زیرسیستم اصلی در خدمتگزار وجود دارد:
1- تجزیهگر[2] ابتدا پرسوجوی ارسالی توسط برنامهی کاربردی را از نظر معتبر بودن نحو[3] بررسی میکند. اگر نحو درست باشد، یک درخت تجزیه ایجاد و بازگردانده میشود. در غیر این صورت، یک خطا بازگردانده میشود. سپس درخت تجزیه به فرمول داخلی استفاده شده توسط پایگاه دادهی back-end تبدیل میشود.
2- پلیس ترافیک[1]، پرسوجو را به عنوان پرسوجوی مفید[2] یا پیچیده شناسایی میکند. پرسوجوهای پیچیده در PostgreSQL انتخاب، درج، بهروزرسانی و پاک میشوند. این پرسوجوها به مرحلهی بعد (بازنویس[3]) ارسال و پرسوجوهای سودمند به فرمانهای سودمند فرستاده میشوند.
3- فرمانهای سودمند، پرسوجوهایی که به مدیریت پیچیده نیاز ندارند را مدیریت میکنند. دستورات vacuum، نسخهبرداری[4]، تغییر دادن[5]، ایجاد[6] جدول، ایجاد نوع[7] و بسیاری دیگر توسط فرمانهای سودمند مدیریت میشوند.
4- بازنویس پرسوجو، زیرسیستمی میان تجزیهگر و برنامهریز[8] است. این زیرسیستم درخت تجزیهی عبوری از پلیس ترافیک را پردازش میکند و با اعمال هر قانون قابلاجرای موجود، درخت را به شکل متناوب بازنویسی میکند. در این مرحله PostgreSQL به منظور پشتیبانی سیستم قانونی قدرتمند برای مشخصات view و بهروزرسانی viewهای مبهم فعال میشود.
5- برنامهریز، یک برنامهی اجرایی بهینه را برای یک پرسوجوی داده شده فراهم میکند. ایدهی اصلی برنامهریز، انتخاب بهترین برنامه برای یک پرسوجو بر اساس تخمین هزینه است. برنامهریز ابتدا تمام راههای پویش[9] و پیوستن[10] ارتباطات ظاهرشده در یک پرسوجو را ترکیب میکند. تمام مسیرهای ایجادشده منجر به ایجاد نتیجهی یکسان میشوند و برنامهریز هزینهی اجرای هر مسیر را تخمین میزند. پس از همهی اینها کمهزینهترین مسیر انتخاب و به اجراکننده فرستاده میشود.
6- اجراکننده[11]، برنامهی ایجادشده توسط برنامهریز را میگیرد و پردازش بالاترین گره را آغاز میکند. اجراکننده، یک درخت برنامهایی را اجرا میکند که شبکهی تقاضا-کشش[12] خط لولهی گرههای پردازششده است. هر گره در زمان فراخوانی در رشتهی خروجی خود چندتایی بعدی را تولید میکند. گرههای موجود در سطوح بالاتر گرههای متصل هستند. هر گرهی متصل هر دو دنبالهی چندتایی ورودی را به یک دنباله تبدیل میکند. در مقابل، گرههای موجود در سطوح پایین، پویشی از جدولهای فیزیکی یا پویش ترتیبی[13] یا پویش نمایهای[14] را ترکیب میکنند. اجراکننده از سیستم ذخیرهسازی استفاده میکند درحالیکه ارتباطات پویششده عملیات مرتب کردن و پیوند را اجرا و شرایط را ارزیابی و در نهایت چندتاییهای مشتقشده[15] را باز میگرداند.
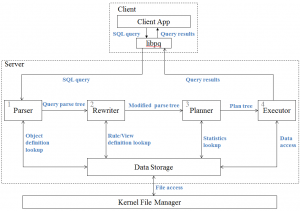
فهرست مراحل برای پاسخگویی به پرس و جو: جریان کاری پرسوجو در پایگاه داده PostgreSQL
در شکل 5 جریان کاری پرسوجو مشاهده میشود. این جریان از مراحل مختلفی تشکیل شده است که در ادامه به آنها پرداخته میشود.
- رشتهی پرس وجوی SQL به درخت پرسوجو تبدیل میشود.
- درخت پرسوجو توسط بازنویس به صورت زیر تغییر میکند:
بازنویس در درخت پرسوجو به دنبال کلمات کلیدیمیگردد و آن را با توجه به تعاریف ارائهشده گسترش میدهد.
- برنامهریز، درخت تجزیهی تغییریافته را میگیرد و تمام مسیرهای پرسوجوی ممکن را تولید میکند. سپس برای تعیین مسیر بهینه و ایجاد برنامهی پرسوجو برای این مسیر، مسیرهای ایجادشده را ارزیابی میکند.
- برنامهی پرسوجو به مجموعههایی از پرسوجوهای SQL قابل اجرا تبدیل و برای دستیابی به نتایج، پردازش میشوند.
[1] Traffic Cop
[2] Utility
[3] Rewriter
[4] Copy
[5] Alter
[6] Create
[7] Type
[8] Planner
[9] Scanning
[10] Joining
[11] Executor
[12] Demand-pull
[13] Sequential
[14] Index
[15] Derived
[1] Data flow
[2] Parser
[3] Syntax
منبع:
http://www.inf.fu-berlin.de/lehre/WS09/DBS-Tech/Material/ConceptArchPostres.pdf
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 9798
برچسبdata base DBMS PostgreSQL RDBMS پایگاه داده پایگاه داده PostgreSQL پستگراسکیوال پستگرس دیتابیس معماری معماری PostgreSQL معماری مفهومی
نوشته های مرتبط







همچنین ببینید
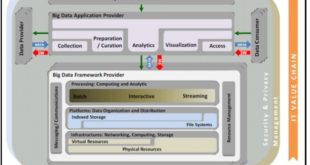
مدل مرجع معماری بیگ دیتا NBDRA (ISO 20547-3)
به بیان ساده، بیگ دیتا مجموعه داده های بزرگ و پیچیده تری هستند، که از منابع …
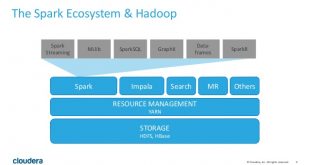
درآمدی بر اسپارک (Spark) و بررسی معماری و اجزای آن
معماری اسپارک (Spark): این تکنولوژی، چارچوبی با کاربرد همه منظوره است و میتوان از آن …
