 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
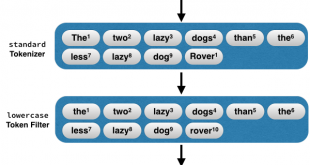
تشخیص موجودیت های اسمی یا نامدار (NER)
فراییند تشخیص موجودیت های اسمی (NER) named entity recognition برای تشخیص اسامی و نوع آنها به کار می رود. تشخیص موجودیت های اسمی فرآیندی است که هدف از آن تشخیص و شناسایی کلمات یا عباراتی است که نمایانگر یک موجودیت میباشند. برای تشخیص موجودیت های اسمی از قبیل نام افراد، سازمانها، مکانها و غیره بکار میرود. همچنین به طور خاص میتواند ما را در حل مسائلی مانند رفع ابهام و تشخیص هویت اصلی بین اشخاصی با اسامی مشترک از روی موضوع متن و با کمک ابزارهای جانبی، یافتن نقل قول و ارجاعات در مقالات علمی یا یافتن ارتباط بین مقالات، تشخیص ارتباط میان اشخاص و انجمنها با استفاده از اسامی و ارجاعات، بهینه کردن پاسخهای یک موتورِ جستجو در زمینهی یافتن اسامی و غیره یاری دهد.

امروزه برای عبارت “موجودیت نامدار” تعاریف متعددی ارائه شده است. تا جایی که در بعضی از منابع تا بیش از 20 تعریف متفاوت از موجودیت نامدار ارائه شده است. از جمله نمونه های ابزار های انگلیسی تشخیص موجودیت های اسمی (NER)، میتوان به Stanford NER و Illinois NER اشاره کرد. در فرایند متن کاوی تشخیص موجودیت های اسمی، بعد مراحلی مثل تشخیص زبان، واحدساز، ریشه یابی کلمات و برچسب گذاری انجام می گیرد.
عناوين مطالب: '
کاربردهای NER
برای تشخیص اینکه یک کلمه اسم است، راه های مختلفی وجود دارد که از جمله ی آنها مراجعه به لغت نامه، استفاده از وردنت، در نظر گرفتن ریشه ی کلمه، استفاده از قواعد نحوی ساخت واژه و غیره می باشد. تشخیص درست واحدهای اسمی، یک نیاز مهم در حل مسائلی در حوزههای جدید مانند پرسش و پاسخ، تحلیل روند، طبقه بندی اسناد، برچسب زنی خودکار متن، پاسخگویی به سوالات، سیستمهای خلاصهسازی، بازیابی اطلاعات، استخراج اطلاعات، ترجمهی ماشینی، تفسیر ویدئویی و جستجوی معنایی در وب و بسیاری کاربردهای دیگر است.
روشهای تشخیص موجودیت های نامدار
تا به امروز، سه رویکرد سنتی برای تشخیص موجودیت های نامدار ارائه شده است و سیستم های مدرن تشخیص موجودیتهای نامدار عمدتا از ترکیب این سه روش استفاده میکنند:
- روشهای مبتنی بر واژه نامه
- روشهای مبتنی بر قواعد
- روش های مبتنی بر یادگیری ماشین
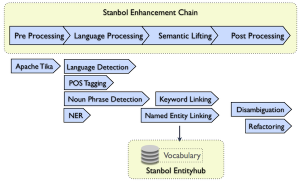
معرفی Stanford-CoreNlp از ابزارهای تشخیص موجودیت های اسمی (NER)
Stanford-CoreNlp مجموعهای از ابزارهای آنالیز متن را در اختیار ما قرار میدهد. این ابزار متن خام انگلیسی را به عنوان ورودی دریافت میکند و کلمات استخراج شده از آن، مقوله واژگانی و برچسب موجودیت را برمیگرداند. به علاوه این ابزار میتواند ساختار جملات را تعیین و مشخص کند کدام عبارات اسمی به چه موجودیتهایی اشاره دارند. استفاده از این ابزار با چند خط کد و بسیار ساده است. به طور خلاصه این ابزار شامل امکانات زیر میباشد:
- The part of speech tagger
- The name entity recognizer (NER)
- The parser
- The coreference resolution system
NER Stanford پیاده سازی شده به زبان جاواست. در این ابزار از دستهبندی کننده CRF بهره گرفته شده و شامل مدل 4 کلاسه که روی دادهی آموزشی CoNLL آموزش دیده، مدل 7 کلاسه که روی MUC آموزش دیده و مدل 3 کلاسه که روی هر دوی این دادههای آموزشی آموزش دیده شده میباشد. برچسب موجودیت در این مدلها عبارتند از:
- 3 کلاس: Location, Person, Organization
- 4 کلاس: Location, Person, Organization, Misc
- 7 کلاس: Time, Location, Organization, Person, Money, Percent, Date
معرفی Lbj-Tagger
این ابزار پیاده سازی شده به زبان جاواست و امکان برچسب زنی موجودیت را در اختیار ما قرار میدهد. این ابزار شامل فهرست موجودیتهای خاص زیر برای زبان انگلیسی میباشد:
- اعداد اصلی ( یک، دو، سه، …)
- اعداد ترتیبی (اول، دوم، …)
- شرکتهای شناخته شده (فورد، فیسبوک، …)
- واحد پول ( دلار، دینار، …)
- کشورها
- مشاغل (بازیگر، …)
- اسامی ( علی، احمد، …)
- ملیتها
- ایالات
- عناوین (ریاست جمهوری، وزیر کشور، …)
- واحد اندازهگیری (متر، لیتر، …)
- کلمات زمانی (ثانیه، هفته، …)
- محصولات هنری (قلعه حیوانات، …)
- رخدادها و مسابقات ورزشی ( لیگ برتر اسپانیا، …)
- فیلمهای سینمایی شناخته شده
- محصولات ساخت دست بشر( آپولو13،…)
- سازمانها
- مشاهیر
- آهنگهای شناخته شده
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 4410
برچسبNamed Entity Recognition NER تشخیص عبارات اسمی تشخیص موجودیت نامدار تشخیص موجودیت های اسمی (NER) موجودیت نامدار موجودیت های اسمی موجودیت های نامدار
نوشته های مرتبط










همچنین ببینید

شناسایی موجودیت های نام دار و ایجاد پیوند معنایی با روش هستان شناسي
آشنایی اولیه ای مقوله پیوند موجودیت های نامدار در مبحث وب معنایی پیوند معنایی موجودیت …
مجموعه داده اسامی مکان برای تشخیص موجودیت های مکانی در پردازش زبان طبیعی
عناوين مطالب: 'مقدمه ای بر اسامی مکان:کاربردهای (Named-entity recognition) NERروشهای تشخیص اسم مکاندانلود دیتاست اسامی …
